Redis (Remote Dictionary Server) — это распределённое хранилище данных в памяти, которое часто используется как база данных, кэш или брокер сообщений.
База из документации
Redis — это программное обеспечение с открытым исходным кодом (лицензия BSD), представляющее собой хранилище структур данных в памяти, которое используется в качестве базы данных, кэша, брокера сообщений и движка для потоковой передачи данных. Redis предоставляет структуры данных, такие как строки, хэши, списки, множества, отсортированные множества с запросами диапазона, битовые карты, гиперлоглоги, геопространственные индексы и потоки. Redis имеет встроенную репликацию, скрипты на Lua, вытеснение по алгоритму LRU, транзакции и различные уровни сохранения данных на диск, а также обеспечивает высокую доступность через Redis Sentinel и автоматическое разделение с помощью Redis Cluster.
Вы можете выполнять атомарные операции с этими типами данных, такие как добавление к строке; увеличение значения в хеше; добавление элемента в список; вычисление пересечения, объединения и разности множеств; или получение элемента с наивысшим рейтингом в отсортированном множестве.
Для достижения высокой производительности Redis работает с набором данных в памяти. В зависимости от вашего случая использования Redis может сохранять ваши данные, периодически сбрасывая набор данных на диск или добавляя каждую команду в журнал на диске. Вы также можете отключить сохранение данных, если вам нужен только функциональный, сетевой, кэш в памяти.
Redis поддерживает асинхронную репликацию с быстрой неблокирующей синхронизацией и автоматическим переподключением с частичной ресинхронизацией после разрыва сети.
Какие структуры данных поддерживает Redis?
- Строки (Strings):
- Самый базовый тип данных в Redis.
- Используется для хранения текстовых или двоичных данных.
- Поддерживает операции, такие как установка значения, получение значения, конкатенация и инкрементирование/декрементирование числовых значений.
- Хэши (Hashes):
- Подобны строкам, но работают с полями и значениями внутри ключа.
- Отлично подходят для представления объектов (например, записей пользователя).
- Списки (Lists):
- Представляют собой коллекции строк, упорядоченные в порядке вставки.
- Подходят для реализации структур данных, таких как очереди или стеки.
- Множества (Sets):
- Неупорядоченные коллекции строк.
- Позволяют быстро проверять наличие элемента, добавлять и удалять элементы, а также выполнять операции над множествами (пересечение, объединение, разность).
- Отсортированные множества (Sorted Sets):
- Похожи на множества, но каждый элемент ассоциирован со “счетчиком”, который используется для упорядочивания элементов.
- Идеально подходят для рейтингов, где порядок элементов часто меняется.
- Битовые карты (Bitmaps):
- Не отдельный тип данных, а представление строк как массивов битов.
- Полезны для выполнения битовых операций и могут быть использованы для эффективного представления данных, где каждый бит имеет значение.
- Гиперлоглоги (HyperLogLogs):
- Проблизительная структура данных, используемая для эффективного подсчета уникальных элементов (кардинальности).
- Геопространственные индексы (Geospatial Indexes):
- Позволяют хранить географические данные и выполнять запросы на основе расстояния.
- Потоки (Streams):
- Новый тип данных, добавленный в Redis 5.0.
- Представляют собой журналы сообщений или событий и идеально подходят для построения систем распределенных очередей сообщений.
Преимущества
- Высокая производительность благодаря хранению данных в памяти.
- Гибкость за счёт поддержки различных структур данных.
- Простота масштабирования и поддержки отказоустойчивых конфигураций.
Недостатки
- Ограниченность памяти: Объём хранимых данных ограничен объёмом доступной оперативной памяти.
- Управление памятью: Требует внимательного управления памятью и настроек для предотвращения потери данных.
Функция репликации Redis
Репликация Redis - это процесс, который позволяет экземплярам быть точными копиями главных экземпляров. По умолчанию репликация является асинхронным процессом. Репликация Redis не блокируется ни на стороне главного экземпляра, ни на стороне реплики. Это означает, что главный экземпляр будет продолжать обрабатывать запросы, когда одна или несколько реплик выполняют начальную синхронизацию или частичную пересинхронизацию.
Реплики для чтения улучшают пропускную способность чтения и защищают от потери данных в случае отказа узла. Репликацию можно использовать как для масштабируемости, чтобы иметь несколько реплик для запросов только на чтение, так и просто для повышения безопасности данных и высокой доступности.
Кроме того, что по умолчанию они доступны только для чтения, одно важное отличие между главным экземпляром и репликой заключается в том, что реплики не удаляют/не вытесняют ключи, они ждут, пока главный экземпляр удаляет ключи, и когда мастер экземпляр удаляет или вытесняет ключ, реплика генерирует команду DEL, которая передается всем репликам.
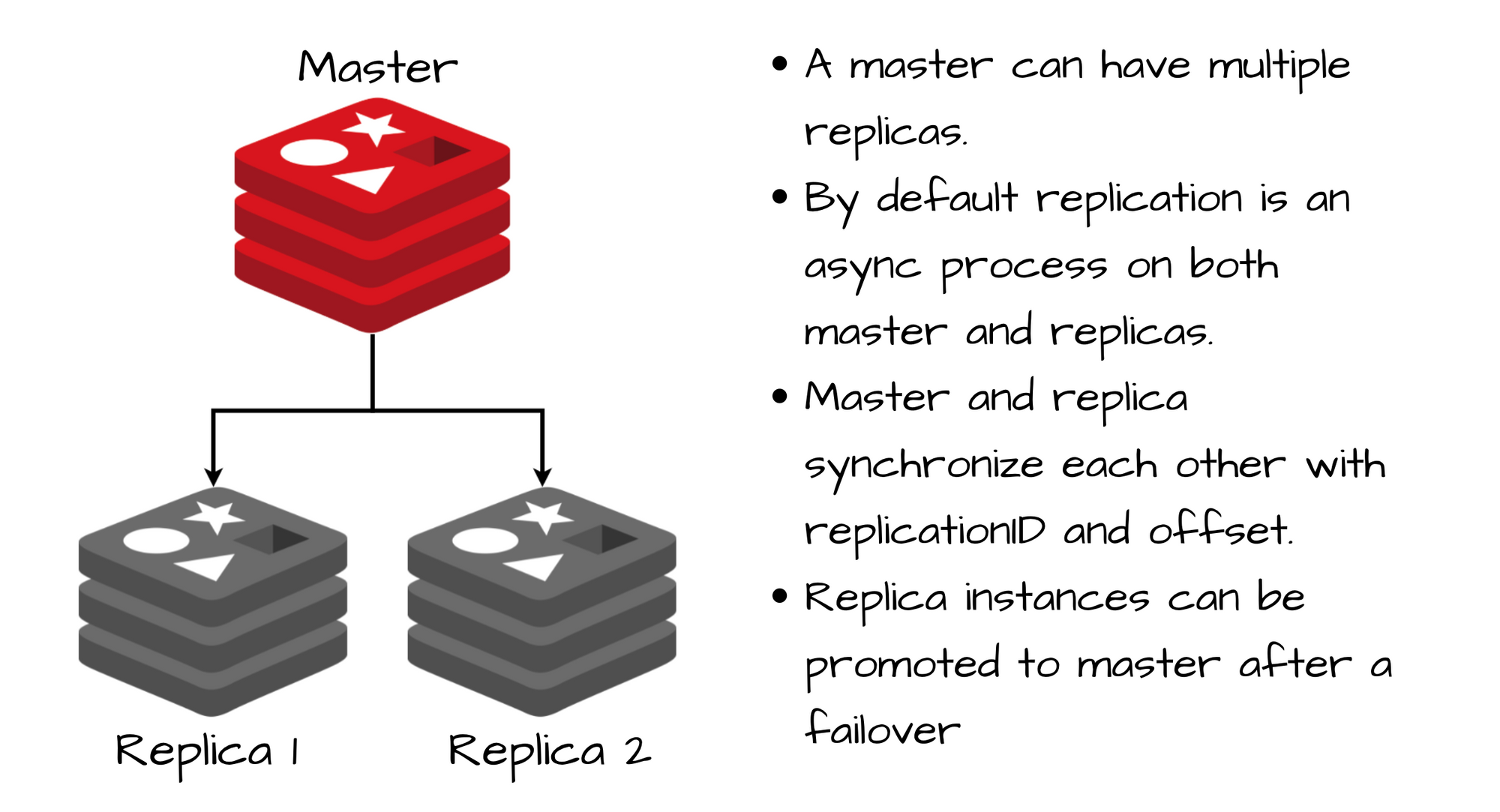
Репликация использует три основных механизма:
-
Когда главный экземпляр и реплики хорошо соединены, главный экземпляр обновляет реплику, отправляя поток команд реплике для воспроизведения изменений в наборе данных, происходящих на стороне главного экземпляра из-за: записей клиентов, истечения срока действия ключей или их вытеснения, любых других действий, изменяющих набор данных главного экземпляра.
-
Когда связь между главным экземпляром и репликой прерывается из-за сетевых проблем или из-за обнаружения тайм-аута главным экземпляром или репликой, реплика переподключается и пытается провести частичную пересинхронизацию: это означает, что она попытается получить только ту часть потока команд, которую она пропустила во время отключения.
-
Когда частичная пересинхронизация невозможна, реплика запрашивает полную пересинхронизацию. Это включает в себя более сложный процесс, при котором главному экземпляру необходимо создать снимок всех своих данных, отправить его реплике, а затем продолжать отправлять поток команд по мере изменения набора данных.
Важные факты о репликации Redis:
- Redis использует асинхронную репликацию, с асинхронным подтверждением репликами главному экземпляру о количестве обработанных данных.
- У главного экземпляра может быть несколько реплик.
- Реплики могут принимать соединения от других реплик. Помимо подключения нескольких реплик к одному главному экземпляру, реплики также могут быть подключены к другим репликам в каскадной структуре. Начиная с Redis 4.0, все подчиненные реплики будут получать точно такой же поток репликации от главного экземпляра.
- Репликация Redis не блокируется на стороне главного экземпляра. Это означает, что главный экземпляр будет продолжать обрабатывать запросы, когда одна или несколько реплик выполняют начальную синхронизацию или частичную пересинхронизацию.
- Репликация также в значительной степени неблокирующая на стороне реплики. В то время как реплика выполняет начальную синхронизацию, она может обрабатывать запросы, используя старую версию набора данных, если вы настроили Redis таким образом в redis.conf. В противном случае, вы можете настроить реплики Redis так, чтобы возвращать клиентам ошибку, если поток репликации прерван. Однако, после начальной синхронизации старый набор данных должен быть удален, и новый должен быть загружен. Реплика будет блокировать входящие соединения в течение этого короткого времени (которое может быть длительным для очень больших наборов данных). Начиная с Redis 4.0, вы можете настроить Redis так, чтобы удаление старого набора данных происходило в другом потоке, однако загрузка нового начального набора данных все равно будет происходить в главном потоке и блокировать реплику.
- Репликацию можно использовать как для масштабирования, чтобы иметь несколько реплик для запросов только на чтение (например, медленные операции O(N) можно перенести на реплики), так и просто для повышения безопасности данных и высокой доступности.
- Вы можете использовать репликацию, чтобы избежать затрат на запись полного набора данных главным экземпляром на диск: типичная техника включает настройку вашего главного экземпляра redis.conf для избежания сохранения на диск вообще, а затем подключить реплику, настроенную для сохранения время от времени, или с включенным AOF. Однако эту конфигурацию необходимо использовать с осторожностью, поскольку перезапускающийся главный экземпляр будет начинаться с пустого набора данных: если реплика попытается синхронизироваться с ним, реплика также будет очищена.
Обеспечивает ли Redis скорость и долговечность одновременно?
Нет, Redis намеренно снижает надежность ради повышения скорости. В Redis в случае сбоя или сбоя системы Redis записывает на диск, но может отстать и потерять данные, которые не сохранены.
Варианты использования
- Кэширование: Часто используется для кэширования данных, например, результатов запросов к базе данных или вывода страниц, для ускорения доступа к часто запрашиваемым данным.
- Сессии: Redis широко используется для хранения данных сессий в веб-приложениях.
- Очереди сообщений: Используется в качестве брокера сообщений для обработки очередей задач и асинхронной обработки.
- Счётчики и статистика: Используется для реализации счётчиков, мониторинга и сбора статистики в реальном времени.
- Геопространственные данные: Redis имеет встроенную поддержку геопространственных индексов и запросов.
В чем разница между DEL и UNLINK в Redis?
Команды DEL и UNLINK используются для удаления ключей, но они работают по-разному:
- DEL (Delete):
- Немедленное удаление: Команда
DELнемедленно удаляет ключи из базы данных Redis. Когда вы исполняетеDELна ключе, Redis сразу же освобождает память, занимаемую этим ключом. - Блокировка: Поскольку
DELвыполняется синхронно, это может привести к блокировке сервера Redis на время удаления, особенно если удаляются большие ключи или наборы ключей. Это может быть проблемой в высокопроизводительных средах, где важно минимизировать задержки.
- Немедленное удаление: Команда
- UNLINK (Unlink):
- Отложенное удаление: Введенная в версии 4.0, команда
UNLINKудаляет ключи асинхронно. Это означает, чтоUNLINKинициирует удаление, но фактическое освобождение памяти происходит в фоновом потоке, позволяя серверу Redis продолжать обработку других команд без значительных задержек. - Производительность: Поскольку
UNLINKработает асинхронно, она предпочтительнее для использования в средах, где важна производительность, особенно при удалении больших ключей или больших наборов ключей.
- Отложенное удаление: Введенная в версии 4.0, команда
Конвейрная обработка в Redis
Конвейерная обработка (pipeline) в Redis — это техника оптимизации производительности, позволяющая уменьшить количество задержек при отправке и получении запросов между клиентом и сервером Redis. Этот метод особенно полезен при выполнении большого количества независимых команд.
В чем проблема и зачем использовать?
Клиенты и серверы Redis общаются друг с другом с использованием протокола под названием RESP (REdis Serialization Protocol), который базируется на TCP. В TCP-ориентированном протоколе сервер и клиент общаются по модели запрос/ответ. Redis работает таким же образом: клиент отправляет запрос, сервер обрабатывает команду, а клиент в блокирующем режиме ожидает ответа. Теперь рассмотрим случай, когда нам нужно выполнить команды SET или GET сотни раз; если идти обычным путем, каждая команда займет некоторое время на круговой поездке (Round Trip Time, RTT), и это повторится для всех команд, что не является оптимальным. В таких случаях мы можем использовать конвейерную обработку Redis.
Конвейеры предоставляют способ передачи нескольких команд на сервер Redis за одну передачу или за один сетевой вызов. Это удобно для пакетной обработки, например, для сохранения всех значений в списке в Redis или для последовательного получения нескольких значений. Конвейеризация по сути является сетевой оптимизацией, при которой все команды группируются на стороне клиента и отправляются одновременно. Давайте посмотрим, как на самом деле работает конвейер Redis изнутри. Прежде чем двигаться дальше, давайте создадим некоторые записи, которые мы позже извлечем с использованием конвейерной обработки Redis.
Какие различные модули доступны в Redis?
- Redisearch:
- Позволяет полнотекстовый поиск, вторичные индексы и агрегации в Redis. Этот модуль особенно полезен для поиска по большим текстовым документам или для создания сложных запросов на данных, хранящихся в Redis.
- RediJSON:
- Предоставляет поддержку JSON-данных в Redis. Этот модуль позволяет хранить, обновлять и получать JSON-объекты, используя Redis, делая его полезным для приложений, которые требуют гибкого и динамического хранения данных.
- RedisGraph:
- Реализует графовую базу данных на основе Redis. Этот модуль поддерживает графовые структуры данных и запросы с использованием языка запросов Cypher, что делает его идеальным для отношений между данными и графовых вычислений.
- RedisTimeSeries:
- Предназначен для эффективного хранения, обновления и запроса временных рядов в Redis. Он подходит для мониторинга, статистики и исторических данных.
Чем Pub/Sub отличается от потоков в Redis?
| Функция | Pub/Sub в Redis | Потоки в Redis |
|---|---|---|
| Модель Взаимодействия | Модель публикации-подписки, где производители отправляют сообщения на канал, а потребители подписываются на каналы. | Последовательности сообщений, сохраняемые в журнале, с возможностью чтения и восстановления после отключений. |
| Хранение Сообщений | Сообщения не сохраняются, доступны только в реальном времени. | Сообщения сохраняются, доступны для чтения в любое время. |
| Использование | Идеально подходит для рассылки уведомлений и сценариев в реальном времени. | Подходит для сложных сценариев с сохранением сообщений и отслеживанием их статуса. |
| Масштабируемость и Надежность | Масштабируем по числу подписчиков, но нет гарантии доставки, если подписчики не подключены. | Высокая масштабируемость и надежность, поддержка работы с большими объемами сообщений. |
| Модель Доставки | Модель “оповещения” с доставкой активным подписчикам в реальном времени. | Потребители самостоятельно извлекают данные в любое время. |
| Сценарии Применения | Рассылка уведомлений, шаблон проектирования Observer. | Надежный обмен сообщениями, комплексная обработка данных. |
Основные Отличия
- Хранение Сообщений: Pub/Sub не сохраняет сообщения, в то время как потоки сохраняют их, что позволяет повторно обрабатывать и анализировать данные.
- Модель Доставки: Pub/Sub - это модель “оповещения”, где сообщения доставляются активным подписчикам в реальном времени. Потоки позволяют потребителям самостоятельно извлекать данные в любое время.
- Сценарии Применения: Pub/Sub лучше подходит для рассылки уведомлений и реализации шаблона проектирования Observer, тогда как потоки идеальны для надежного обмена сообщениями и комплексной обработки данных.
Как Redis реализует очередь?
Что такое выселение в Redis?
Выселение в Redis (eviction) относится к процессу автоматического удаления ключей из базы данных, когда она достигает своего предела памяти. Этот механизм позволяет Redis продолжать операции записи, даже когда доступная память ограничена.
Политики выселения
1. noeviction
- Описание: При достижении лимита памяти Redis не будет выселять ключи. Вместо этого он вернёт ошибку при попытке записать новые данные.
- Использование: Эта политика подходит, когда важно не терять данные и вы готовы контролировать использование памяти внешними средствами.
2. allkeys-lru
- Описание: Redis выселяет ключи, которые были использованы (читались или записывались) давно, из всего набора ключей.
- Использование: Эффективно для кэширования, где менее часто используемые данные могут быть удалены.
3. volatile-lru
- Описание: Аналогично
allkeys-lru, но применяется только к ключам с установленным сроком жизни (TTL). - Использование: Подходит, если вы хотите выселять только те ключи, которые имеют TTL, сохраняя при этом ключи без TTL.
4. allkeys-random
- Описание: Выбирает случайные ключи для выселения из всего набора ключей.
- Использование: Может быть использовано в сценариях, где равномерность выселения важнее, чем сохранение часто используемых ключей.
5. volatile-random
- Описание: Выбирает случайные ключи для выселения среди тех, у которых установлен TTL.
- Использование: Подобно
allkeys-random, но сосредотачивается только на ключах с TTL.
6. volatile-ttl
- Описание: Выбирает для выселения ключ с наименьшим TTL из тех, у которых он установлен.
- Использование: Полезно, когда хотите приоритезировать выселение ключей, у которых ближе всего истечение TTL.
7. volatile-lfu (доступно с Redis 4.0)
- Описание: Использует алгоритм LFU (Least Frequently Used) для выселения ключей с TTL, выбирая те, что используются наименее часто.
- Использование: Подходит для сценариев, где предпочтение отдаётся сохранению часто запрашиваемых ключей.
8. allkeys-lfu (доступно с Redis 4.0)
- Описание: Похоже на
volatile-lfu, но применяется ко всем ключам, независимо от наличия TTL. - Использование: Идеально подходит для общих сценариев кэширования, где ключи, используемые реже всего, могут быть выселены.
Redis vs Memcached
| Особенность | Redis | Memcached |
|---|---|---|
| Типы данных | Поддерживает различные типы данных (строки, списки, хеши, множества, отсортированные множества и др.) | Ограничен поддержкой простых типов данных (в основном строки) |
| Персистентность | Поддерживает различные уровни персистентности (RDB, AOF) | Не поддерживает персистентность; все данные хранятся в памяти |
| Распределенная архитектура | Поддерживает кластеризацию и репликацию | Нет встроенной поддержки кластеризации, распределение через клиентские библиотеки |
| Производительность | Высокая, с некоторым влиянием от дополнительных функций | Высокая, может быть немного быстрее из-за простоты |
| Поддержка скриптования | Есть (Lua) | Нет |
| Репликация и высокая доступность | Поддерживает продвинутую репликацию и высокую доступность | Ограниченные возможности репликации, нет встроенных механизмов для высокой доступности |
| Применение | База данных, система кэширования, брокер сообщений | В основном используется как система кэширования |
Redis протокол
Redis использует собственный протокол для общения между клиентами и сервером, известный как RESP (REdis Serialization Protocol).
RESP может сериализовать различные типы данных, включая целые числа, строки и массивы. Он также включает специальный тип для ошибок. Клиент отправляет запрос серверу Redis в виде массива строк. Содержимое массива - это команда и ее аргументы, которые сервер должен выполнить. Тип ответа сервера зависит от команды.
RESP является безопасным для двоичных данных и использует префиксную длину для передачи объемных данных, так что не требует обработки объемных данных, передаваемых от одного процесса к другому.
| RESP data type | Minimal protocol version | Category | First byte |
|---|---|---|---|
| Simple strings | RESP2 | Simple | + |
| Simple Errors | RESP2 | Simple | - |
| Integers | RESP2 | Simple | : |
| Bulk strings | RESP2 | Aggregate | $ |
| Arrays | RESP2 | Aggregate | * |
| Nulls | RESP3 | Simple | _ |
| Booleans | RESP3 | Simple | # |
| Doubles | RESP3 | Simple | , |
| Big numbers | RESP3 | Simple | ( |
| Bulk errors | RESP3 | Aggregate | ! |
| Verbatim strings | RESP3 | Aggregate | = |
| Maps | RESP3 | Aggregate | % |
| Sets | RESP3 | Aggregate | ~ |
| Pushes | RESP3 | Aggregate | > |
Фреймворки
>>> import redis
>>> r = redis.Redis(host='localhost', port=6379, db=0)
>>> r.set('foo', 'bar')
True
>>> r.get('foo')
b'bar'