Разница SQL и NoSQL баз данных
- SQL databases use structured query language (SQL) and have a predefined schema. NoSQL databases have dynamic schemas for unstructured data.
- SQL databases are vertically scalable (more power e.g. CPUs), while NoSQL databases are horizontally scalable (more machines).
- SQL databases are table-based, while NoSQL databases are document, key-value, graph, or wide-column stores.
- SQL databases are better for multi-row transactions, while NoSQL is better for unstructured data like documents or JSON.
Транзакции
Что такое транзакция
Транзакция — это элементарная операция в базе данных.
Однако транзакция может состоять и из нескольких операций: в этом ключе — это логически целостная процедура, в которой должны быть выполнены либо все операции — либо ни одна из них.
Транзакция начинается с команды BEGIN и заканчивается командой commit либо отменяется командой rollback
Какие есть уровни изоляции транзакций?
| Уровень изоляции | «Грязное» чтение | Неповторяемое чтение | Фантомное чтение | Аномалия сериализации |
|---|---|---|---|---|
| Read uncommitted | Допускается, но не в PG | Возможно | Возможно | Возможно |
| Read committed | Невозможно | Возможно | Возможно | Возможно |
| Repeatable read | Невозможно | Невозможно | Допускается, но не в PG | Возможно |
| Serializable | Невозможно | Невозможно | Невозможно | Невозможно |
Базовый уровень изоляции в PostgreSQL – Read Committed.
Причина наличия в PostgreSQL только трёх уровней изоляции состоит в том, что только так можно сопоставить стандартные уровни изоляции с архитектурой многоверсионного управления конкурентным доступом.
Базовый уровень изоляции в MySQL – Repeatable read.
”Грязное” чтение: Транзакция читает данные, записанные параллельной незавершённой транзакцией.
Неповторяемое чтение: Транзакция повторно читает те же данные, что и раньше, и обнаруживает, что они были изменены другой транзакцией (которая завершилась после первого чтения).
Фантомное чтение: Транзакция повторно выполняет запрос, возвращающий набор строк для некоторого условия, и обнаруживает, что набор строк, удовлетворяющих условию, изменился из-за транзакции, завершившейся за это время.
Аномалия сериализации: Когда невозможно предсказать в каком порядке выполнятся транзакции. Важно, когда берем проценты от числа.
- 1000 * 110% + 1000 = 2100
- (1000 + 1000) * 110% = 2200
Как выбрать нужный уровень транзакции?
Для выбора нужного уровня изоляции транзакций используется команда SET TRANSACTION.
ACID (atomicity, consistency, isolation, durability)
ACID — набор требований к транзакционной системе, обеспечивающий наиболее надёжную и предсказуемую её работу
-
Атомарность гарантирует, что каждая транзакция будет выполнена полностью или не будет выполнена совсем. Не допускаются промежуточные состояния.
-
Констистетность, то есть до выполнения операции и после база остается постоянной.
-
Изолированность. Во время выполнения транзакции параллельные транзакции не должны оказывать влияния на её результат.
- Блокировки — это когда мы блокируем данные в базе.
- Версии — это когда внутри базы при каждом обновлении создается новая версия данных и сохраняется старая.
-
Надежность. Если пользователь получил подтверждение от системы, что транзакция выполнена, он может быть уверен, что сделанные им изменения не будут отменены из-за какого-либо сбоя.
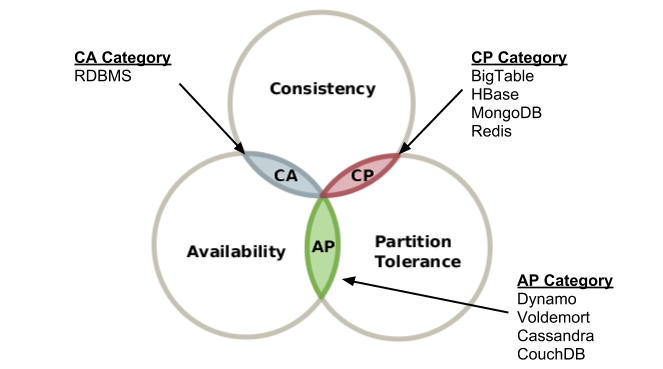
CAP теорема
Теорема CAP — эвристическое утверждение о том, что в любой реализации распределённых вычислений возможно обеспечить не более двух из трёх следующих свойств
- согласованность данных (англ. consistency) — во всех вычислительных узлах в один момент времени данные не противоречат друг другу;
- доступность (англ. availability) — любой запрос к распределённой системе завершается корректным откликом, однако без гарантии, что ответы всех узлов системы совпадают;
- устойчивость к разделению (англ. partition tolerance) — расщепление распределённой системы на несколько изолированных секций не приводит к некорректности отклика от каждой из секций.
SQL
Общие вопросы
VARCHAR vs CHAR
varchar используется для строк символов переменной длины, тогда как Char используется для строк фиксированной длины
Unique key
Уникальный ключ нужен для обеспечения неповторяемости значений в таблице. Это означает, что есть колонка в таблице, значения в которой не могут повторяться на протяжении всей таблицы и каждая строка или запись таблицы могут однозначно идентифицироваться по этому уникальному ключу. Уникальный ключ может состоять из нескольких столбцов или полей таблицы.
Уникальных ключей в таблице может быть несколько, тогда как первичный может быть только один.
Какие бывают типы подзапросов?
Существует два типа подзапросов, а именно: коррелированные и некоррелированные.
- Коррелированный подзапрос: это запрос, который выбирает данные из таблицы со ссылкой на внешний запрос. Он не считается независимым запросом, поскольку ссылается на другую таблицу или столбец в таблице.
- Некоррелированный подзапрос: этот запрос является независимым запросом, в котором выходные данные подзапроса подставляются в основной запрос.
Какие есть типы связей?
Есть три типа связей:
- 1 к 1: данные о сотрудниках дочерних отделов (почти всегда такие таблицы объединяются)
- 1 ко многим: у одного клиента может быть несколько телефонов, но в тоже время мы можем быть уверены в том, что один конкретный номер может быть только у одного клиента
- много ко многим: первое — одну книгу может написать несколько авторов, второе — автор может написать несколько книг.
Функции в SQL
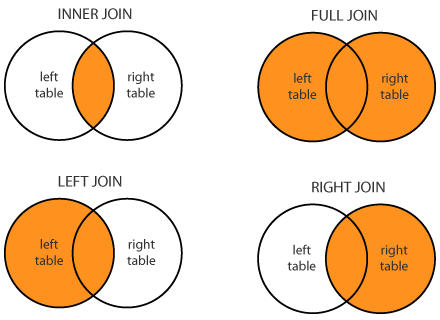
Виды JOIN’ов
CROSS VS NATURAL JOIN
Перекрестное соединение создает перекрестное или декартово произведение двух таблиц, тогда как естественное соединение основано на всех столбцах, имеющих одинаковое имя и типы данных в обеих таблицах.
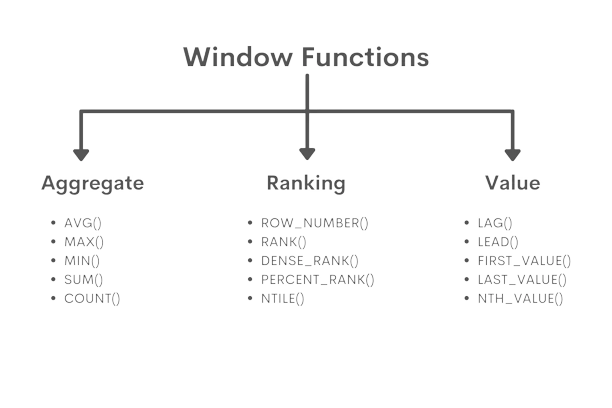
Оконные функции
Оконная функция в SQL — функция, которая работает с выделенным набором строк (окном, партицией) и выполняет вычисление для этого набора строк в отдельном столбце.
MERGE
Merge позволяет сделать операцию UPDATE, INSERT, DELETE без предварительного SELECT данных из таблицы. Он используется, когда надо надо данные из одной таблицы перебросить в другую.
UPSERT
UPSERT позволяет выполнять команду insert если запись уже существует (с такими уникальными значениями),
EXPLAIN
Это удобное средство, которое помогает оптимизировать запросы. С помощью инструкций EXPLAIN можно получать информацию о том, как выполняются инструкции SQL.
EXPLAIN ANALYSE
As you correctly mention, the difference between explain & explain analyze is that the former generates the query plan by estimating the cost, while the latter actually executes the query. Thus, explain analyze will give you more accurate query plan / cost.
SET операции
UNION
Комбинирует результат 2х и более SELECT запросов. Таблицы для UNION запросы должны иметь одинаковое:
- кол-во колонок
- типы колонок
- порядок колонок
INTERSECT
Возвращает общие строки из 2х и более SELECT запросов.
EXCEPT
Возвращает строки из первого SELECT, которые не появятся во втором.
DELETE vs TRUNCATE
| DELETE | TRUNCATE |
|---|---|
| Используется для удаления строки в таблице | Используется для удаления всех строк из таблицы |
| Вы можете восстановить данные после удаления | Вы не можете восстановить данные (прим. перевод.: операции логируются по разному, но в SQL Server есть возможность сделать откат) транзакции |
| DML-команда | DDL-команда |
| Медленнее, чем оператор TRUNCATE | Быстрее |
Запросы
Как разобраться почему запрос долго работает?
- Анализ запроса. Проверьте, не запрашиваете ли вы слишком много данных, есть ли правильные соединения и джойны между таблицами.
- Используйте EXPLAIN, которая показывает план выполнения запроса, какие индексы используются, какие шаги занимают больше всего времени и т. д.
- Индексы. Убедитесь, что у вас есть необходимые индексы для столбцов, которые часто используются в условиях WHERE, JOIN и ORDER BY. Не стали ли индексы фрагментированными или неоптимальными со временем?
- Оптимизация запросов
- Мониторинг ресурсов (например, ЦПУ, память, диск).
- Метрики производительности базы данных, такие как время отклика, очередь запросов и т. д.
- Проверить логи базы данных на наличие ошибок или предупреждений, связанных с вашим запросом или другими аспектами работы СУБД.
- Сетевые задержки
CTE (Common Table Expression)
Common Table Expression (CTE) представляет собой временный набор результатов, который используется в рамках SQL-запроса и существует только в течение выполнения этого запроса. CTE облегчает написание сложных запросов, делая их более читаемыми и удобными для поддержки.
CTE определяется с помощью ключевого слова WITH, за которым следует имя CTE и определение набора данных. Эти данные можно затем использовать в основном запросе или в других CTE в том же запросе.
Пример простого CTE в SQL:
WITH TemporaryTable AS (
SELECT column1, column2
FROM some_table
WHERE condition
)
SELECT *
FROM TemporaryTable
WHERE another_condition;Как оптимизировать запрос?
Прогнать через EXPLAIN ANALYZE.
-
Оптимизация кода
- Вместо звездочки использовать имена столбцов
- Дополнительный
WHERE - Уменьшайте количество
JOINв запросе, если это возможно. - Используйте
INNER JOINвместоOUTER JOIN, где это уместно, так какINNER JOINобычно более эффективен. - Избегайте использования операторов, таких как
LIKE '%...%', которые могут предотвратить использование индексов. - Для запросов, возвращающих большое количество строк, используйте пагинацию с
LIMITиOFFSET
-
Сведите к минимуму использование подзапросов.
Используйте оператор
INаккуратно, поскольку на практике он имеет низкую производительность и может быть эффективен только при использовании критериев фильтрации в подзапросе. -
Использовать
WITH& DatabasesCommon Table Expressions — временные таблицы, которые создаются только в рамках выполнения какой-либо операции и удаляются, как только становятся не нужны.
-
Разбиение Больших Таблиц (Partitioning)
-
Использование Кэширования: Кэширование результатов часто выполняемых запросов на уровне приложения или использование встроенных механизмов кэширования базы данных может значительно уменьшить нагрузку.
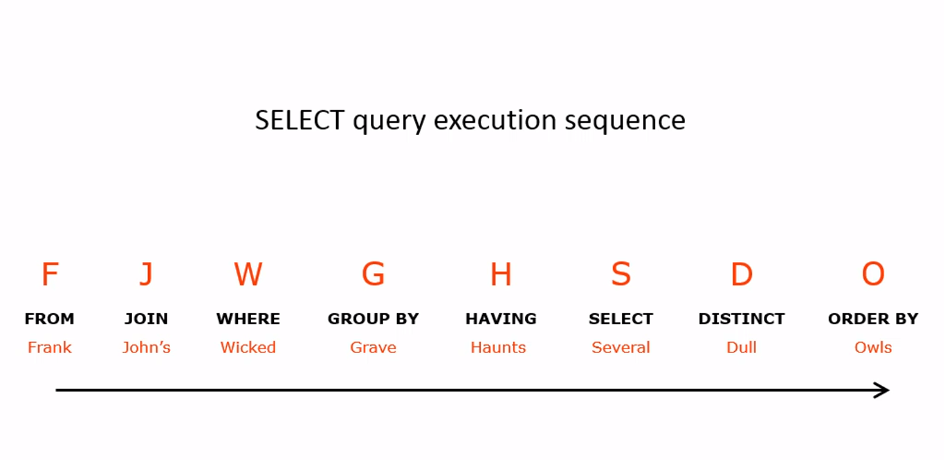
Порядок обработки запроса
Множества SQL
DDL (Data Definition Language)
DDL – это набор запросов, которые определяют и управляют структурой БД, такие как:
CREATE– создание таблиц/схемALTER– изменение таблиц/схем (удаление, добавление колонок, изменение их типов)
ALTER TABLE table_name
ACTION column_name data_type constraints;DROP– удаление таблиц/схемTRUNCATE,COPY– очистка данных в таблиц, копирование таблицы
DML (Data Manipulation Language)
DML – набор запросов на правление и модификацию данных в таблицах: вставка, обновление и выборка данных.
INSERTUDPATEDELETESELECTWHERE– фильтрация
DCL (Data Control Language)
DCL – позволяет контролировать доступ к базе данных.
GRANT(предоставить права)REVOKE(отозвать права).
Индексы
Что такое индекс?
Индекс – это объект базы данных, создаваемый с целью повышения производительности поиска данных.
Не стоит использовать индексы для небольших таблиц. Не стоит использовать индексы для таблиц, в которых, как предполагается, будут часто добавляться новые данные, либо эти данные будут изменяться.
Индекс нужен тогда, когда запросы выполняются часто и долго. Ненужные индексы нужно удалять.
Виды и типы индексов
Виды
- Кластерные индексы хранят данные записей целиком и отдельно.
- Обычные индексы хранят ссылки на записи (PK). Используются отсортированные таблицы, поэтому потребление памяти там меньше.
Разница:
- Различия между кластеризованным и некластеризованным индексами в SQL: Кластерный индекс используется для простого и быстрого извлечения данных из базы данных, тогда как чтение из некластеризованного индекса происходит относительно медленнее.
- Кластеризованный индекс изменяет способ хранения записей в базе данных — он сортирует строки по столбцу, который установлен как кластеризованный индекс, тогда как в некластеризованном индексе он не меняет способ хранения, но создает отдельный объект внутри таблицы, который указывает на исходные строки таблицы при поиске.
- Одна таблица может иметь только один кластеризованный индекс, тогда как некластеризованных у нее может быть много.
Типы
- B-tree
- пространственные индексы (spatial grid)
- hash index
- bitmap
- function based
- reverted
В PostgreSQL могут быть и другие виды – GiST, GIN.
| MySQL | PostgreSQL | MS SQL | Oracle | |
|---|---|---|---|---|
| B-Tree index | Есть | Есть | Есть | Есть |
| Spatial indexes | R-Tree с квадратичным разбиением | Rtree_GiST(используется линейное разбиение) | 4-х уровневый Grid-based spatial index (отдельные для географических и геодезических данных) | R-Tree c квадратичным разбиением; Quadtree |
| Hash index | Только в таблицах типа Memory | Есть | Нет | Нет |
| Bitmap index | Нет | Есть | Нет | Есть |
| Reverse index | Нет | Нет | Нет | Есть |
| Inverted index | Есть | Есть | Есть | Есть |
| Partial index | Нет | Есть | Есть | Нет |
| Function based index | Нет | Есть | Есть | Есть |
Как можно создать индексы?
- Индекс по столбцу (это чистая классика)
- Индекс по нескольким столбцам
- Уникальный индекс
- Индекс на основе выражения
- Частичный индекс
При этом:
для создания уникального индекса может использоваться слово UNIQUE
для создания выражения его записывают в скобках, например для создания выражения проверки индекса на нижний регистр можно написать так:
. . . ( lower( <column_name> ) ) ;для создания частичного индекса после скобок запись продолжается, например для проверки на величину можно написать так:
. . . ( . . . ) WHERE <column_name> > 1000 ;Index vs PK
A key (minimal superkey) is a set of attributes, the values of which are unique for every tuple (every row in the table at some point in time).
An index is a performance optimisation feature that enables data to be accessed faster.
PK vs FK
PK — однозначно идентифицирует какую-то строку в таблице. FK — для связи таблиц с друг другом
Оба могут состоять более чем из одного столбца.
Как чистить индексы?
DROP INDEX ... on ...VACUUM
Масштабирование БД
Горизонтальное масштабирование: увелечение кол-ва серверов
Вертиклаьное масштабирование: наращивание мощностей сервера
Репликация
Копирование данных между серверами. При использовании такого метода выделяют два типа серверов: master и slave. Мастер используется для записи или изменения информации, слейвы — для копирования информации с мастера и её чтения.
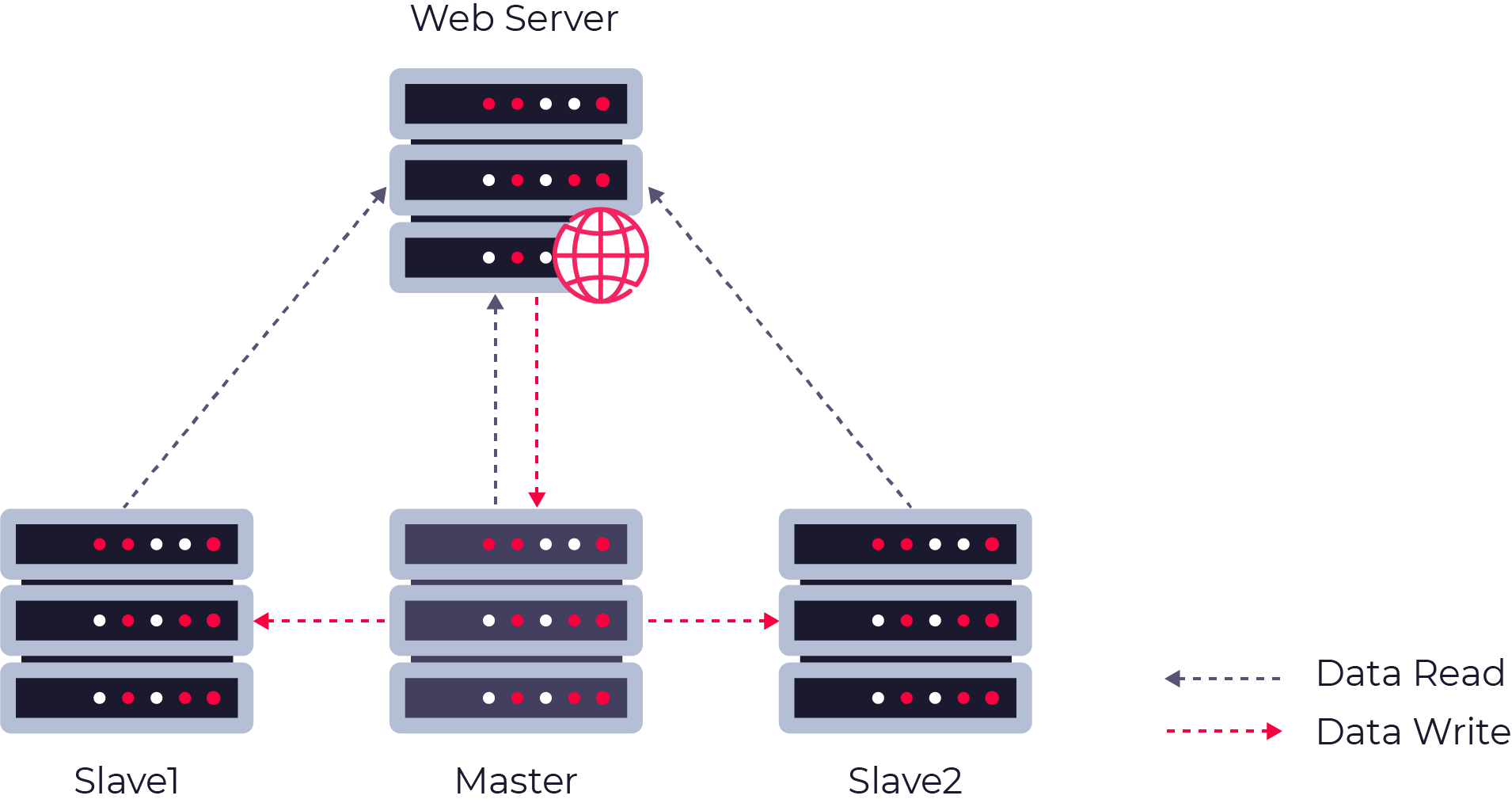
Виды репликаций
Physical (or streaming)
Это репликация, при которой от основного сервера PostgreSQL на реплики передается WAL. И каждая реплика затем по этому журналу изменяет свои данные. Для настройки такой репликации все серверы должны быть одной версии, работать на одной ОС и архитектуре. Потоковая репликация в Postgres бывает двух видов — асинхронная и синхронная.
- Асинхронная репликация. В этом случае PostgreSQL сначала применит изменения на основном узле и только потом отправит записи из WAL на реплики. Преимущество такого способа — быстрое подтверждение транзакции, т.к. не нужно ждать пока все реплики применят изменения. Недостаток в том, что при падении основного сервера часть данных на репликах может потеряться, так как изменения не успели продублироваться.
- Синхронная репликация. В этом случае изменения сначала записываются в WAL хотя бы одной реплики и только после этого фиксируются на основном сервере. Преимущество — более надежный способ, при котором сложнее потерять данные. Недостаток — операции выполняются медленнее, потому что прежде чем подтвердить транзакцию, нужно сначала продублировать ее на реплике.
Logical
Логическая репликация — это метод репликации объектов данных и изменений в них, использующий репликационные идентификаторы (обычно это первичный ключ), оперирует записями
В логической репликации используется модель публикаций/подписок с одним или несколькими подписчиками, которые подписываются на одну или несколько публикаций на публикующем узле. Подписчики получают данные из публикаций, на которые они подписаны, и могут затем повторно опубликовать данные для организации каскадной репликации или более сложных конфигураций.
Логическая репликация таблицы обычно начинается с создания снимка данных в публикуемой базе данных и копирования её подписчику. После этого изменения на стороне публикации передаются подписчику в реальном времени, когда они происходят. Подписчик применяет изменения в том же порядке, что и узел публикации, так что для публикаций в рамках одной подписки гарантируется транзакционная целостность. Этот метод репликации данных иногда называется транзакционной репликацией.
Physical vs Logical
| Характеристика | Физическая репликация (Streaming) | Логическая репликация |
|---|---|---|
| Уровень репликации | На уровне блоков диска (WAL-файлы) | На уровне SQL-запросов (таблицы и строки) |
| Гранулярность | Вся база данных | Выборочные таблицы или даже строки |
| Задержка | Минимальная задержка даже для больших транзакций | Может вызывать задержки для малых транзакций из-за ожидания завершения больших |
| Влияние на реплику | Запросы на чтение могут замедлять репликацию | Нет необходимости отменять долгие запросы, не влияет на репликацию |
| Требования к реплике | Реплика должна быть полной копией основного сервера | На реплике можно выполнять транзакции, создавать временные таблицы и т.д. |
| Обработка DDL | DDL реплицируется автоматически | Требует синхронизации схем вручную или с помощью дополнительных инструментов |
| Ресурсы на реплике | Требует меньше ресурсов для применения изменений | Требует больше ресурсов для применения изменений |
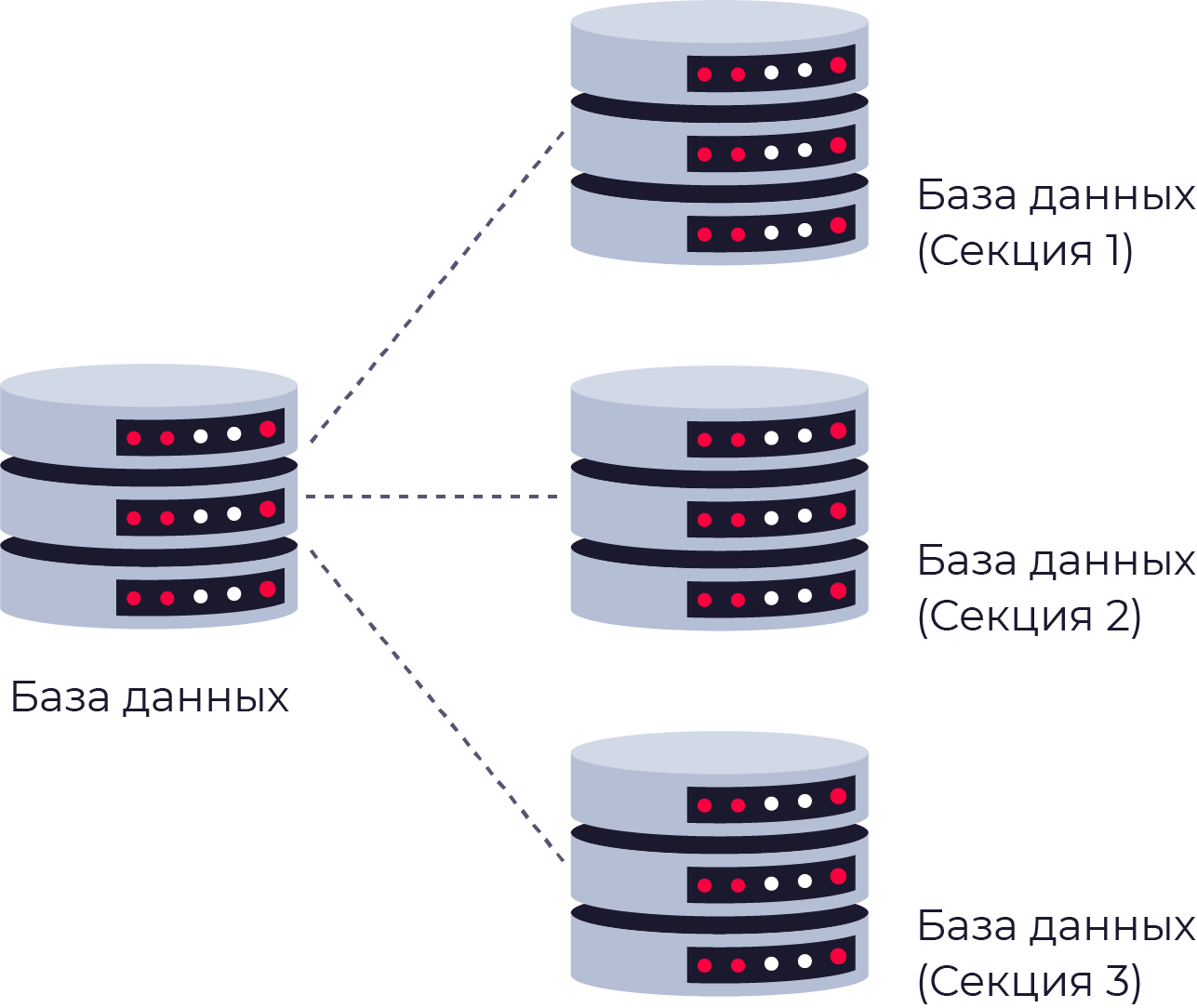
Партицирование
В разбиении данных на части по какому-либо признаку. Например, таблицу можно разбить на две по признаку чётности. поиск осуществляется не по всей таблице, а лишь по её части.
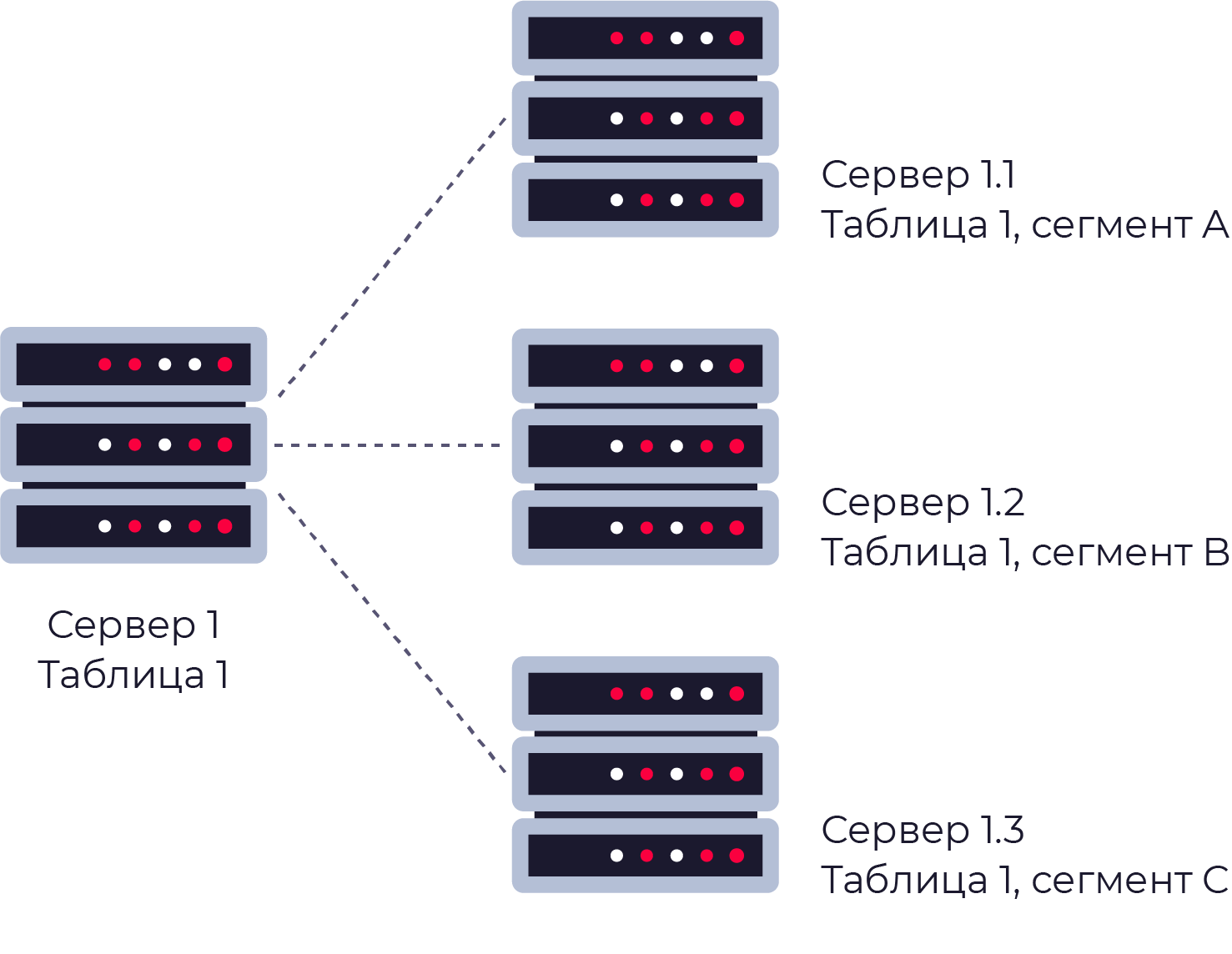
Шардинг
Части таблицы хранятся раздельно, на разных физических серверах.
Нормализация БД
Нормализация — это процесс организации данных в базе данных, включающий создание таблиц и установление отношений между ними в соответствии с правилами, которые обеспечивают защиту данных и делают базу данных более гибкой, устраняя избыточность и несогласованные зависимости.
Избыточность устраняется, как правило, за счёт декомпозиции отношений (таблиц), т.е. разбиения одной таблицы на несколько.
Избыточность данных – это когда одни и те же данные хранятся в базе в нескольких местах, именно это и приводит к аномалиям.
Нормальные формы БД:
| Форма | Концепт |
|---|---|
| 1NF | - нет дублирующихся строк в таблице - все атрибуты простые (атомарные) |
| 2NF = 0 + 1NF | - у таблицы должен быть первичный ключ PK - все атрибуты должны описывать первичный ключ полностью, а не только какую-то его часть |
| 3NF = 0 + 2NF | Не должно быть зависимостей одних неключевых атрибутов от других |
| BOYCE-CODD NORMAL FORM (BCNF OR 3.5NF) = 0 + 3NF | Несколько полей имеют нетривиальную и неприводимую слева функциональную зависимость, которую можно вынести в отдельную таблицу |
| 4NF = 0 + BCNF | {Ресторан, Вид пиццы, Район доставки} → декомпозиция в: {Ресторан} → {Вид пиццы} {Ресторан} → {Район доставки} |
Как можно оптимизировать запрос с частичным поиском по строке?
LIKE- Используйте индексы:
- Для запросов, начинающихся с определенной подстроки (например,
LIKE 'substring%'), обычный индекс может быть эффективным. - Для запросов с подстрокой в середине или в конце строки, рассмотрите возможность использования полнотекстового индекса (Full-Text Index). Во многих СУБД, таких как MySQL и PostgreSQL, есть поддержка полнотекстового поиска.
- Для запросов, начинающихся с определенной подстроки (например,
Что такое SQL Injection?
Это атака на базу данных, которая позволит выполнить некоторое действие, которое не планировалось создателем скрипта.
Триггеры БД
Триггеры представляют обработчики событий. Они выполняются при наступлении какого-либо простого действия в SQL. Такими действиями обычно являются: удаление, вставка и обновление данных.
Курсоры
Курсоры – некое подмножество из таблицы, результирующий набор данных, в которым можно выполнять операции с отдельными строками.
Хранимые процедуры и функции
Хранимые процедуры позволяют содержать часто используемый SQL запрос на сервере. Это обеспечивает лучшую производительность, поскольку данный запрос должен анализироваться только однажды и уменьшается трафик между сервером и клиентом.
Хранимые функции - тоже что и процедуры, но при этом возвращают обязательно какое-то значение.
| Плюсы | Минусы |
|---|---|
| Скорость | PL/PGSQL старый и древний язык |
| Управление доступом | Нету менеджера зависимостей. |
| Меньшая вер-ть SQL Injection |
ETL
Extract, Transform, Load — общий термин для всех процессов миграции данных из одного источника в другой.
Типичные этапы ETL-процесса:
- извлечение данных из источника (файл, БД, веб-страница и пр);
- очистка данных (приведение разнородных данных к единому формату, удаление лишнего, устранение недочетов и пр);
- обогащение (применение алгоритмов или внешних источников для получения новых данных, связанных с обрабатываемыми данными);
- трансформирование;
- загрузка (интеграция в единую целевую модель).
Что такое VACUUM в PostgreSQL?
VACUUM высвобождает пространство, занимаемое «мёртвыми» кортежами. При обычных операциях PostgreSQL кортежи, удалённые или устаревшие в результате обновления, физически не удаляются из таблицы; они сохраняются в ней, пока не будет выполнена команда VACUUM .
Произошел сбой, как локализовать проблему?
- Логи
- Трассировки
- Метрики
Трассировка (tracing) и отладка (debugging) — это два различных метода исследования и устранения проблем в программном обеспечении, но они имеют разные цели и используются в разных контекстах.
Трассировка (Tracing)
Определение: Трассировка — это процесс записи последовательности операций или событий в программе. Это часто делается с помощью вставки специальных инструкций в код, которые записывают информацию в лог или другое хранилище.
Цель: Помогает понять, как программа работает “в реальном времени”, идентифицировать узкие места, проблемы производительности или непредвиденные пути выполнения.
Применение: Часто используется в продакшен-системах для мониторинга поведения программы, анализа производительности и выявления аномалий.
Инструменты: Существуют специализированные инструменты для трассировки, такие как Jaeger, Zipkin, OpenTracing и другие.
Отладка (Debugging)
Определение: Отладка — это процесс идентификации, изучения и устранения ошибок или проблем в программном коде.
Цель: Найти и исправить ошибки в программе, чтобы она работала корректно.
Применение: Обычно используется в процессе разработки программного обеспечения, когда разработчик сталкивается с неожиданным поведением или ошибками.
Инструменты: Отладчики (debuggers), такие как GDB, LLDB, pdb (для Python) и многие другие, позволяют разработчикам останавливать выполнение программы, просматривать и изменять значения переменных, анализировать стек вызовов и так далее.
Метрики
Производительность и ресурсы:
- Загрузка ЦПУ
- Использование памяти
- Использование диска
- Пропускная способность сети
- Метрики приложения:
Метрики ошибок:
- Количество исключений или ошибок
- Количество необработанных ошибок
- Количество ошибок по различным категориям или типам
Метрики базы данных:
- Запросы в секунду
- Время отклика запроса
- Размер базы данных
- Количество одновременных соединений
Метрики инфраструктуры:
- Состояние и доступность сервисов
- Время простоя
- Процент использования ресурсов
Планирование запросов
Когда вы отправляете запрос к базе данных, СУБД не просто начинает его исполнять. Сначала она пытается определить наиболее эффективный способ выполнения этого запроса. Этот процесс называется планированием запросов.
- Парсинг запроса: Сначала запрос анализируется, чтобы убедиться, что он синтаксически верен.
- Оценка возможных планов: СУБД рассматривает различные способы выполнения запроса. Например, какие индексы использовать, в каком порядке соединять таблицы и т. д.
- Выбор наилучшего плана: На основе различных метрик (например, стоимости дискового ввода-вывода, ожидаемого количества обрабатываемых строк) СУБД выбирает наиболее оптимальный план выполнения запроса.
- Исполнение плана: После выбора плана СУБД начинает исполнение запроса в соответствии с этим планом.
Селективность
Селективность — это мера того, как много данных будет выбрано из таблицы или индекса в результате выполнения определенного условия в запросе. Селективность может быть выражена как процент или доля от общего числа записей.
- Высокая селективность: Запрос выбирает маленький процент данных из таблицы. Такие запросы обычно эффективнее, так как они обрабатывают меньше данных.
- Низкая селективность: Запрос выбирает большой процент данных из таблицы.
Селективность важна для СУБД при планировании запросов, потому что:
-
Оптимизация использования индексов: Если условие в запросе имеет высокую селективность, то использование индекса может быть очень эффективным. Если селективность низкая, иногда быстрее просканировать всю таблицу, чем использовать индекс.
-
Определение порядка соединения таблиц: Если у вас есть запрос, который соединяет несколько таблиц, селективность условий может влиять на порядок, в котором эти таблицы будут соединены.
PostgreSQL
Типы данных
Все типы тут – PostgreSQL : Документация: 16: Глава 8. Типы данных : Компания Postgres Professional
- Числовые типы:
- Целочисленные:
SMALLINT,INTEGER,BIGINT - Числа с произвольной точностью:
NUMERIC - С плавающей точкой:
REAL,DOUBLE PRECISION
- Целочисленные:
- Символьные типы:
- Фиксированная длина:
CHAR(n)илиCHARACTER(n) - Переменная длина:
VARCHAR(n)илиCHARACTER VARYING(n) - Без ограничения длины:
TEXT
- Фиксированная длина:
- Типы даты/времени:
DATE,TIME,TIMESTAMP,TIMESTAMPTZ,INTERVAL- Включает поддержку часовых поясов и интервалов
- Логический тип (
BOOLEAN) - Типы перечислений (
ENUM) - UUID
- XML
- JSON
- Массивы
- Составные типы (custom types)
Понятия
Atributes (атрибуты)
Атрибуты – это по факту колонка, к которой можно обращаться как table.column_name. У неё есть:
- имя
- тип данных
- constraint (not null, unique, check, foreign key)
- default value
Tuples (кортежы)
Кортеж относится к базовой структуре данных, используемой для представления одной записи (или строки) в таблице. Кортеж содержит не только значения данных, но и дополнительную метаинформацию, такую как системные атрибуты e.g.
- идентификатор транзакции, который создал или удалил кортеж
- указатели на физическое местоположение кортежа в файле данных
- т.д.
Constraints
С помощью ключевого слова CONSTRAINT можно задать имя для ограничений.
- PK
- FK
- Unique
- Check
- Not Null
- Exclude
Имена ограничений можно задать на уровне столбцов. Они указываются после CONSTRAINT перед атрибутами.
MVCC
MVCC (Multi-Version Concurrency Control) – это механизм управления параллельным доступом к данным в базе данных, который широко используется в PostgreSQL и других СУБД для поддержки одновременных транзакций.
Фишка в том, что в базе данных допускается существование нескольких «версий» одного и того же элемента данных
Преимущества
- Изоляция транзакций. В каждой транзакции свой “взгляд” на БД, что защищает на просмотр чужой незакомиченной даты.
- Concurrency. Несколько транзакций одновременно можно запускать.
Как работает
- Получение transaction ID (TXID).
- Чтение данных, которые закоммичены и изменений, которые собираемся сделать.
- При операциях изменения (INSERT, UPDATE, or DELETE), создается новая версия с измененными строками и новая версия вешается на TXID – создается новый кортеж.
- Другие транзакции увидят только “старые данные”.
- Когда транзакция закоммичена, то проверяем, что нет конфликтов.
Недостаток метода в том, что получаем storage overhead – много версий БД много весят.
Транзакции в PG
Транзакции в PG следуют ACID. Ключевые понятия:
BEGIN: Запускает новую транзакцию.COMMIT: Завершает текущую транзакцию и закрепляет все изменения, сделанные во время транзакции, постоянными.ROLLBACK: Отменяет все изменения, сделанные во время текущей транзакции, и завершает транзакцию.SAVEPOINT: Создает точку сохранения, к которой вы можете позже вернуться.ROLLBACK TO savepoint: Откатывает транзакцию к указанной точке сохранения.RELEASE savepoint: Удаляет точку сохранения, что позволяет зафиксировать изменения, сделанные с момента создания точки сохранения.
BEGIN; -- Start a transaction
INSERT INTO employees (name, salary) VALUES ('Alice', 5000);
INSERT INTO employees (name, salary) VALUES ('Bob', 6000);
-- Other SQL statements...
COMMIT; -- Commit the transaction and make changes permanent
-- In case of an issue, you can use ROLLBACK to revert changes
ROLLBACK; -- Roll back the transaction and undo all changesLock models
PostgreSQL предоставляет lock modes, такие как FOR UPDATE, FOR NO KEY UPDATE, FOR SHARE, and FOR KEY SHARE.
BEGIN;
SELECT * FROM my_table WHERE id = 1 FOR UPDATE;
-- Perform updates or deletions here
COMMIT;Если одна транзакция заблокировала строки с помощью этой команды, тогда параллельные транзакции не смогут заблокировать эти же строки до тех пор, пока первая транзакция не завершится, и тем самым блокировка не будет снята.
Обработка запроса
- Parsing. SQL код разбивается на мелкие компоненты и создается parse tree, структура данных, которая отображет элементы запроса
- Rewriting. Это может включать удаление ненужных условий, упрощения выражений, применения проверок безопасности.
- Optimisation. Построения лучшего плана запроса с помощью анализа доступностью индексов, размера таблиц, сложность условий запроса. Делается расчет стоимости каждого плана.
- Возврат результата.
Утилиты
systemd– система инициализации и менеджер системных процессов, используемый во многих современных дистрибутивах Linux. Он отвечает за запуск и управление фоновыми службами (демонами), включая PostgreSQL.pg_ctl– низкоуровневая утилита, предназначенная для запуска, остановки, перезапуска и управления экземплярами сервера PostgreSQL.- pg_ctlcluster – утилита, которая предоставляет высокоуровневый интерфейс для управления кластерами PostgreSQL. Удобно для пользователей, у которых несколько кластеров PG на одной системе.
psql– утилита для управления PG сервером, с которой можно делать любые операции с БД
Сравнение PgSQL с другими СУБД
MySQL vs PostgreSQL
PostgreSQL быстрая open-source СУБД, а MySQL более прост в настройке.
Улучшенная конкурентность в Postgres засчет MVCC, который поддерживает параллельный доступ.
| PostgreSQL | MySQL | |
|---|---|---|
| Architecture | Object relational; multiprocess | Relational; single process |
| Data types supported | Numeric, date/time, character, boolean, enumerated, geometric, network address, JSON, XML, HSTORE, arrays, ranges, composite https://www.postgresql.org/docs/current/datatype.html | Numeric, date/time, character, spatial, JSON https://dev.mysql.com/doc/refman/8.0/en/data-types.html |
| Indexes supported | B-tree, hash, GiST, SP-GiST, GIN, and BRIN | Primarily B-tree; R-tree, hash, and inverted indexes for certain data types |
| Performance | Suited for applications with high volume of both reads and writes | Suitable for applications with high volume of reads |
| Security | Access control, multiple encrypted connection options https://www.postgresql.org/docs/13/runtime.html | Access control, encrypted connections https://dev.mysql.com/doc/refman/8.0/en/security.html |
Cassandra vs PostgreSQL
Домены
Домены в PostgreSQL представляют собой способ определения пользовательских типов данных, основанных на уже существующих типах данных. Они позволяют накладывать дополнительные ограничения на столбцы в таблицах.
CREATE DOMAIN posint AS integer CHECK (VALUE > 0);
CREATE TABLE mytable (id posint);
INSERT INTO mytable VALUES(1); -- работает
INSERT INTO mytable VALUES(-1); -- ошибкаWAL
WAL (Write-Ahead Logging) в PostgreSQL – это стандартный метод обеспечения целостности данных, который играет ключевую роль в обеспечении целостности данных и поддержке восстановления после сбоев.
Изменения в файлах с данными (где находятся таблицы и индексы) должны записываться только после того, как эти изменения были занесены в журнал, т. е. после того как записи журнала, описывающие данные изменения, будут сохранены на постоянное устройство хранения. Если следовать этой процедуре, то записывать страницы данных на диск после подтверждения каждой транзакции нет необходимости, потому что мы знаем, что если случится сбой, то у нас будет возможность восстановить базу данных с помощью журнала: любые изменения, которые не были применены к страницам с данными, могут быть воссозданы из записей журнала. (Это называется восстановлением с воспроизведением, или REDO.)
Результатом использования WAL является значительное уменьшение количества запросов записи на диск, потому что для гарантии, что транзакция подтверждена, в записи на диск нуждается только файл журнала, а не каждый файл данных изменённый в результате транзакции.
MATERIALIZED VIEW и VIEW
VIEW – это как ярлык или ссылка на один или несколько запросов в вашей базе данных. Когда вы запрашиваете данные через представление, база данных каждый раз выполняет запросы, чтобы получить актуальную информацию. Представление не занимает дополнительного места, так как в нем не хранятся реальные данные, оно просто “показывает” данные, которые уже есть в базе.
MATERIALIZED VIEW – это похоже на создание снимка определенных данных и сохранение его на диске. Это значит, что данные уже вычислены и доступны для быстрого чтения, но они не обновляются автоматически вместе с изменениями в основных таблицах. Вам нужно будет время от времени обновлять (или “обновлять”) этот снимок, чтобы он отражал последние изменения в данных.
CREATE VIEW customer_view AS
....
CREATE MATERIALIZED VIEW customer_summary ASСравнение
| VIEW | MATERIALIZED VIEW | |
|---|---|---|
| Хранение | Виртуальная таблица, не хранится на диске. | Физическая копия базовой таблицы, хранится на диске. |
| Обновление | Автоматически обновляется при изменении данных в базовых таблицах. | Требует ручного обновления или обновления с помощью триггеров. |
| Производительность | Медленнее, так как данные вычисляются при каждом запросе. | Быстрее, так как данные предварительно вычислены и сохранены. |
| Предварительное вычисление | Отсутствует, вычисляется при каждом доступе. | Присутствует, данные сохраняются на диске. |
| Преимущества | Не требует дополнительного места на диске. Может ограничить доступ к данным, упрощает запросы. | Быстрее обрабатывает запросы благодаря предварительному хранению данных. |
| Изменяемость | Не все представления поддерживают обновление. | Необходимо обновлять вручную или с помощью триггеров. |
В каких случаях они полезны
Представления (VIEW) полезны для:
- Упрощения сложных запросов: Если вы часто выполняете сложные запросы, то можете сохранить их как представление, чтобы упростить повторное использование.
- Ограничения доступа: Можете показывать пользователям только определенные данные, не предоставляя доступ ко всей таблице.
Материализованные представления (MATERIALIZED VIEW) полезны для:
- Ускорения чтения данных: Поскольку данные уже вычислены и сохранены, запросы к материализованному представлению выполняются гораздо быстрее, особенно если исходные данные требуют длительных операций агрегации или соединения.
- Снижения нагрузки на базу данных: При работе с большими объемами данных и сложными запросами, которые не нуждаются в реальном времени, материализованные представления могут снизить частоту и сложность вычислений, выполняемых базой данных.
LATERAL
LATERAL JOIN в PostgreSQL очень полезен в тех случаях, когда нужно получить данные из одной таблицы или подзапроса, и эти данные зависят от значений в другой таблице или подзапросе. Он позволяет использовать значения из предыдущих элементов обработки запроса в последующих элементах.
Конфигурирование PostgreSQL
Задается двумя файлами.
-
postgresql.conf: Общее поведение. Параметры:
listen_addresses: Если сервер расположен не на той же машине, что и сам PG, то требуется разрешить подключение с друго сервера. По умолчанию стоит'*'port: This setting determines the TCP port number the server listens on.max_connections: Максимальное кол-во конкурентных соединений.shared_buffers: Эта общая память, которая используется одновременно всеми подключениями. Чем выше объем этих буферов, тем меньше будет нагрузка на диск.work_mem: Объем памяти, который используется каждым подключением для внутренних операций.
-
pg_hba.conf: Управление аутентификацией.
TYPE DATABASE USER ADDRESS METHOD
Дополнительные настройки
Логирование
log_destination: Этот параметр определяет, куда будут записываться журналы, это может быть комбинация stderr, csvlog или syslog.logging_collector: Включает или отключает сбор и перенаправление файлов журнала в отдельный каталог журнала.log_directory: Указывает каталог назначения для файлов журнала (если включенlogging_collector).log_filename: Устанавливает соглашение об именовании и шаблон для файлов журнала (полезно для ротации журнала).log_statement: Определяет уровень SQL-операторов, которые будут записываться в журнал, например none, ddl, mod (модификация данных) или all.
Performance Tuning
effective_cache_size: Указывает общий объем памяти, доступный для кэширования. Этот параметр помогает планировщику запросов оптимизировать выполнение запросов.maintenance_work_mem: Указывает объем памяти, доступный для операций обслуживания, таких как VACUUM и CREATE INDEX.wal_buffers: Определяет объем памяти, выделенной для журнала с опережающей записью (WAL).checkpoint_completion_target(цель завершения контрольной точки): Управляет целью завершения для контрольных точек, что помогает управлять продолжительностью и частотой сброса данных на диск.
PL/pgSQL
PL/pgSQL (англ. Procedural Language/Postgres Structured Query Language) — процедурное расширение языка SQL, используемое в СУБД PostgreSQL.
Postgres WAL Files and Sequence Numbers
Фишки
- Использование собственных типов данных (PG + Кастомные)
- Управление циклом
- Обработка исключений
- Разграничение прав
Пример:
CREATE FUNCTION get_total(customers_id INT) RETURNS INT AS $$
DECLARE
total INT;
BEGIN
SELECT SUM(order_amount) INTO total FROM orders WHERE customer_id = customers_id;
RETURN total;
END;
$$ LANGUAGE plpgsql;Недостатки
- Перенос приложений на другие СУБД может потребовать значительной переработки или полной перезаписи хранимых процедур и функций
- Каждая конструкция языка выполняется сервером отдельно. То есть, если написать какую-то функцию тяжелую, то она будет тормозить все и масштабировать это будет очень тяжело.