to-do
- High Water Mark (HWM) in Kafka Offsets | by Kamini Kamal | Level Up Coding
- и про ребалансировку и нахуй она и когда делается
- куда продюсер писать может?
- вот у нас 3 реплики
- куда он пишет?
- loose coupling event driven
- exactly-once kafka
- Idempotency Keys kafka
- Как подтверждать, что был отправлен и успешно принята какая-то ифна?
Message Queues & Message Brokers
Брокеры сообщений используют очереди сообщений, чтобы передавать информацию. То есть MQ – это струтура данных, которая хранит что-то, а брокер – это софтина, которая управляет этим.
Очереди
Очередь — структура данных с дисциплиной доступа к элементам «первый пришёл — первый вышел». Добавление элемента возможно лишь в конец очереди, выборка — только из начала очереди, при этом выбранный элемент из очереди удаляется.
Брокеры сообщений
Брокер сообщений представляет собой тип построения архитектуры, при котором элементы системы «общаются» друг с другом с помощью посредника. Благодаря его работе происходит снятие нагрузки с веб-сервисов, так как им не приходится заниматься пересылкой сообщений: всю сопутствующую этому процессу работу он берёт на себя.
| Преимущества | Недостатки |
|---|---|
| Асинхронная коммуникация | Нужно управление по мониторингу |
| Отказоустойчивость (fault tolerance) | Дополнительная задержка |
| Гарантии доставки (обеспечивает различные уровни гарантий доставки, включая “хотя бы один раз” и “ровно один раз”) | Зависимость от работы брокера |
| Гибкость в маршрутизации (можно динамически изменять пути сообщений и фильтровать сообщения на основе содержимого или заголовков) | Дополнительные требования к ресурсам |
| Масштабируемость | Дополнительные требования по безопасности |
Когда брокеры сообщений могут быть полезны
- Действия с задержкой, которые не требуют результата сейчас.
- Координация микросервисов.
Семантики доставки
- At-most-once delivery – сообщение не может быть доставлено больше одного раза. При этом сообщение может быть потеряно.
- At-least-once delivery – сообщение никогда не будет потеряно. При этом сообщение может быть доставлено более одного раза.
- Exactly-once delivery. Все сообщения доставляются строго единожды.
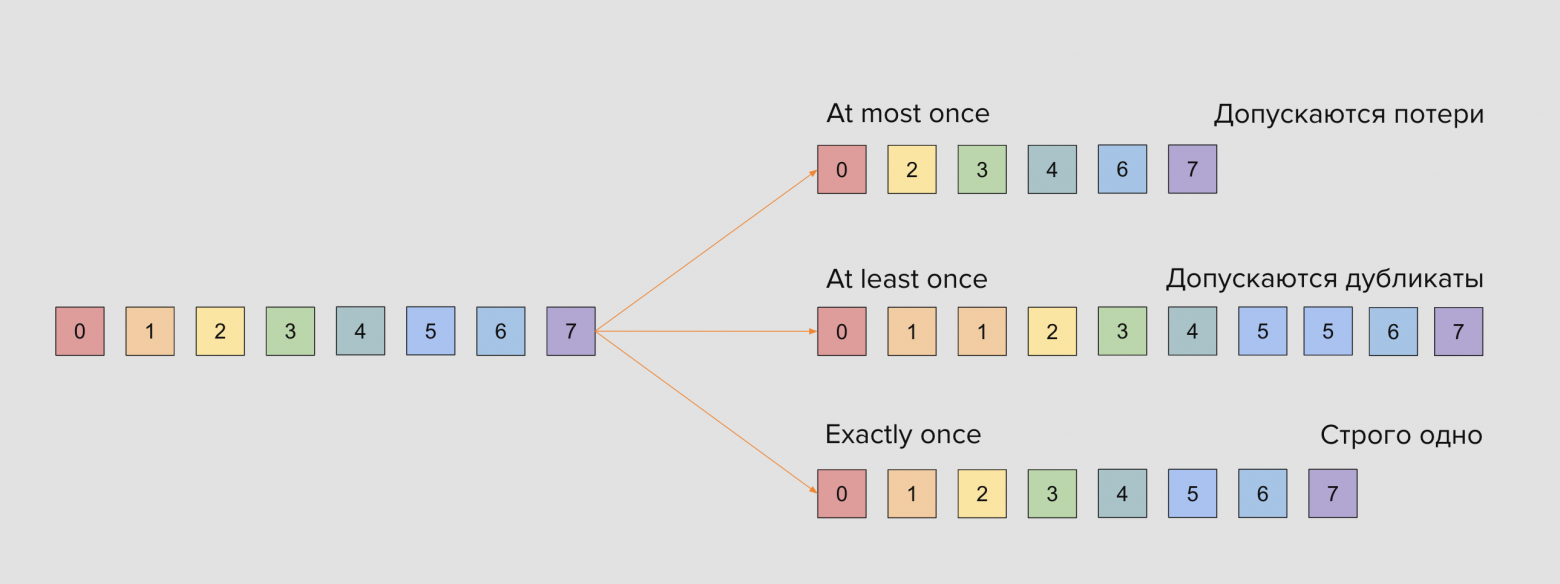
На первый взгляд самой правильной для любого приложения кажется семантика exactly once, однако это не всегда так. Например, при передаче партнёрских координат вовсе не обязательно сохранять каждую точку из них, и вполне хватит at-most once. А при обработке идемпотентных событий нас вполне может и устроить дубль, если статусная модель предполагает его корректную обработку.
В распределённых системах у exactly-once есть своя цена: высокая надёжность означает большие задержки.
End-to-end idempotence – даже при многократной попытке записи или обработки сообщения, в системе будет гарантировано, что сообщение будет обработано точно один раз:
- продьюсеры не будут писать больше одного раза
- консьюмеры будут читать только один раз даже при сбоях
В транзакциях kafka можно сделать, чтобы несколько ивентов схлопались в один
Kafka
Сущности
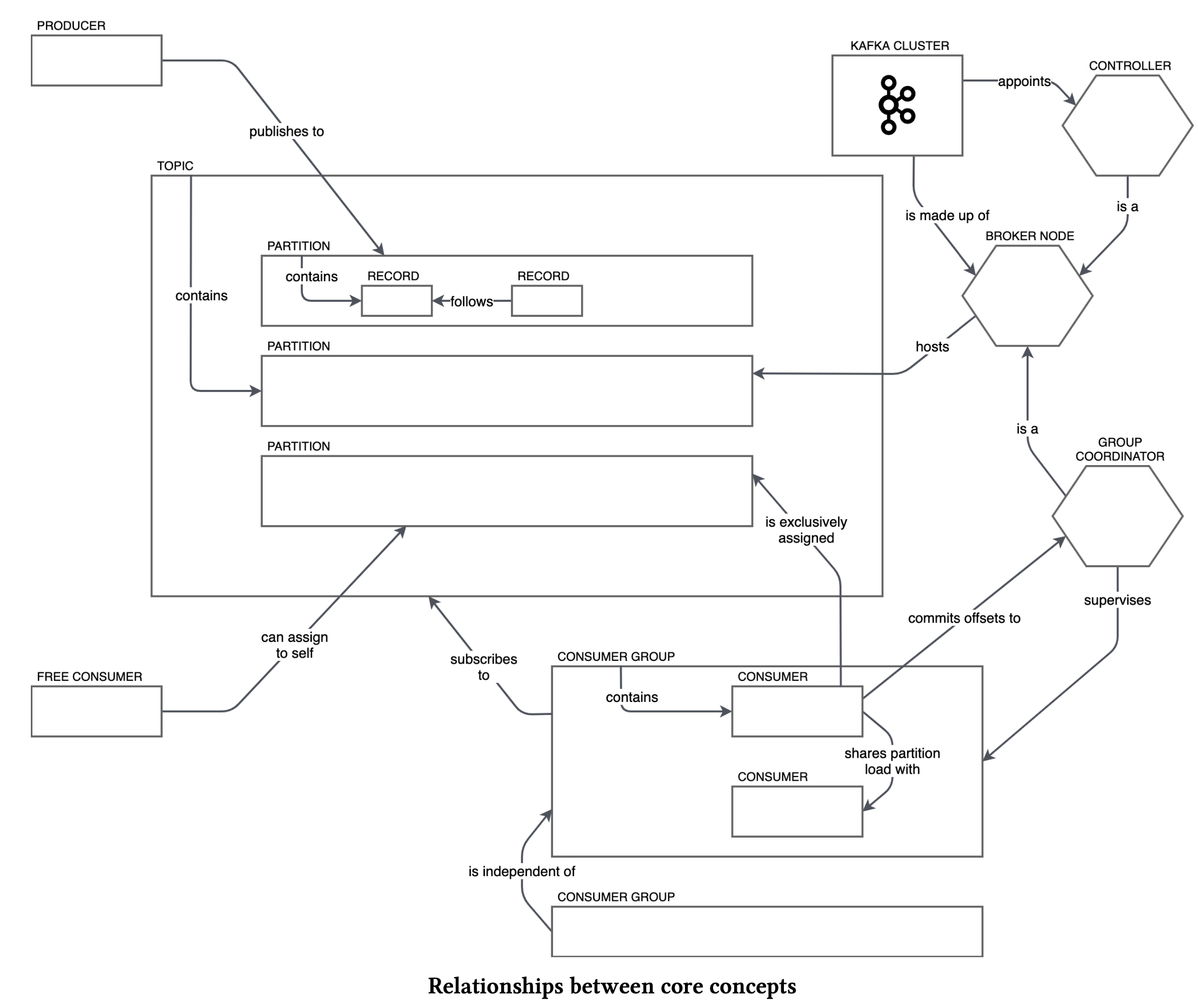
ZooKeeper — инструмент-координатор, действует как общая служба конфигурации в системе. Работает как база для хранения метаданных о состоянии узлов кластера и расположении сообщений.
Kafka Controller — среди брокеров Zookeeper выбирает одного, который будет обеспечивать консистентность данных.
- Топики – это “папка” для сообщений. В топик складывается стрим данных, единая очередь из входящих сообщений.
- Партиции – это упорядоченная последовательность сообщений. Для ускорения чтения и записи топики делятся на партиции. Происходит параллелизация данных. Это конфигурируемый параметр, сообщения могут отправлять несколько продюсеров и принимать несколько консьюмеров.
- Кластеры – один или несколько хостов-брокеров, на которых размещены топики и соответствующие топикам разделы.
- Брокеры – это сервер, который принимает, хранит и обрабатывает потоки данных. Брокеры работают в кластере и объединяются вместе
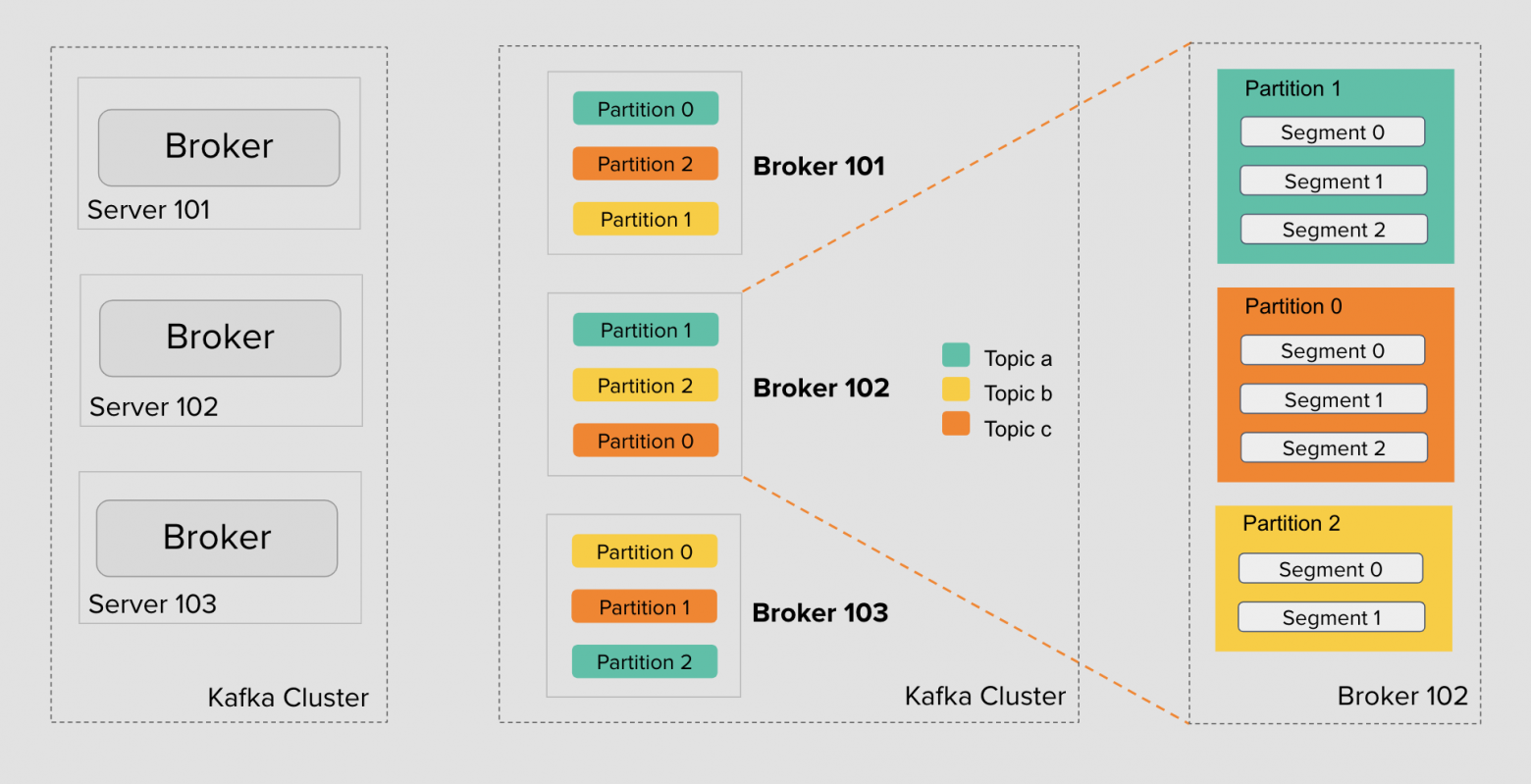
Кластер → Брокеры (сервера) → Топики → Партиции → Сегменты.
Продьюсеры отправляют записи в кластеры, которые хранят записи и далее отправляют их консьюмерам. Каждая нода в кластере – это брокер, который хранит данные переданные продьюсером до тех пор, пока их не вычитает консьюмер.
Продьсюеры
Продюсеры самостоятельно партицируют данные в топиках и сами определяют алгоритм партицирования: он может быть как банальный round-robin и hash-based, так и кастомный.
Очерёдность сообщений гарантируется только для одной партиции.
Гарантии доставки в Kafka
Продюсер сам выбирает размер батча и число ретраев при отправке сообщений. Протокол Kafka предоставляет гарантии доставки всех трёх семантик: at-most once, at-least once и exactly-once.
У exactly-once есть цена. Для надёжной записи необходимо использовать:
- подтверждение как от лидера, так и от реплик
- включить идемпотентность
- использовать транзакционный API
Всё это негативно влияет на время записи.
Если вы хотите писать в Kafka надёжно, указывайте при создании топика min.insync.replicas < общее количество реплик. Иначе можно ничего не записать, т.к. не дождёмся подтверждения записи.
Если указать acks=all, то надо включать и enable.idempotence. Накладных расходов на идемпотентность нет.
Records
Записи – это самый простой юнит в Kafka, event какой-то по факту. Содержит:
- Ключ
- Значение
- Заголовки
- Номер партиции
- Офсет
- Timestamp
Offset
Офсет – это позиция (индекс) сообщения в определенном topic и partition, который указывает на то, какие сообщения были уже прочитаны consumer.
Если консьюмер падает в процессе получения данных, то, когда он запустится вновь и ему нужно будет вернутся к чтению этого сообщения, он воспользуется офсетом и продолжит с нужного места.
Committing offsets
Это процесс, посредством которого консьюмеры в Kafka сообщают брокеру о том, какие сообщения они уже успешно обработали.
В Kafka offsets могут быть автоматически зафиксированы (auto-commit) или управляемы вручную (manual commit).
Зачем нужно commit offsets?
- Для обеспечения доставки “точно один раз” (exactly once delivery): Путем фиксации offsets потребители могут точно отслеживать, до какого момента в потоке данных они продвинулись. Это позволяет избежать повторной обработки уже прочитанных сообщений после перезапуска или сбоя потребителя.
- Для гарантии упорядоченной обработки сообщений: В системах, где порядок сообщений критичен, фиксация offsets обеспечивает возможность следовать этому порядку, даже если произошел сбой или необходимо перераспределить обработку между разными потребителями.
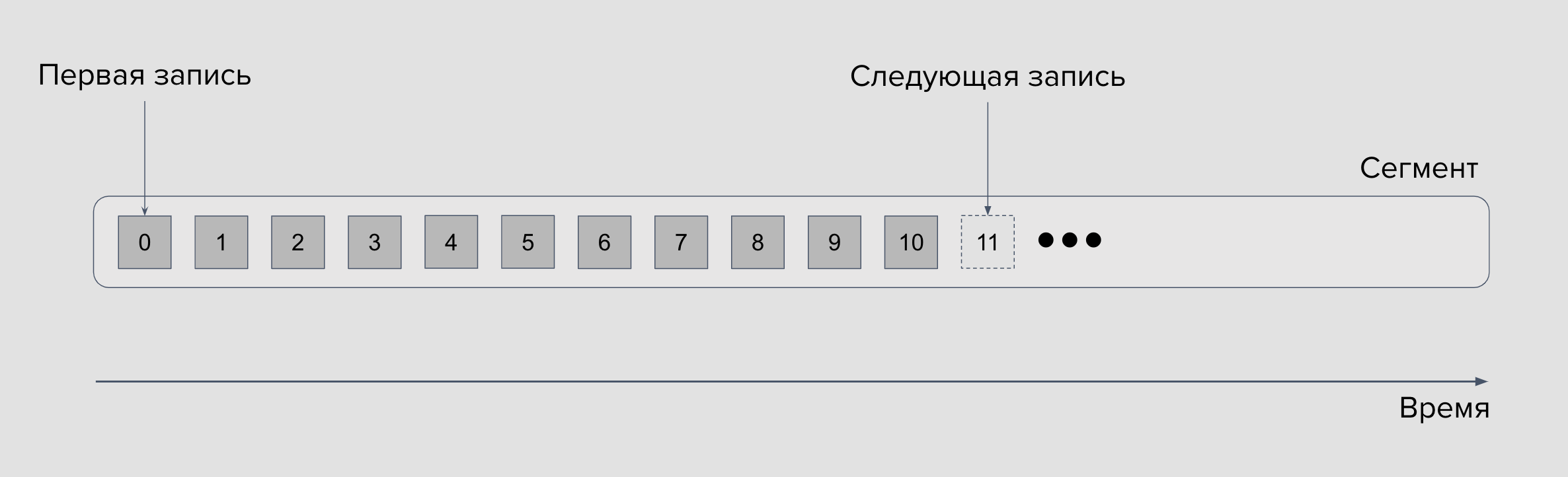
Сегмент
Сегмент тоже удобно представить как обычный лог-файл: каждая следующая запись добавляется в конец файла и не меняет предыдущих записей. Фактически это очередь FIFO (First-In-First-Out) и Kafka реализует именно эту модель.
Семантически и физически сообщения внутри сегмента не могут быть удалены, они иммутабельны. Всё, что мы можем — указать, как долго Kafka-брокер будет хранить события через настройку политики устаревания данных или Retention Policy.
Partition
Партиция — это упорядоченная и неизменяемая последовательность сообщений, которая хранит данные внутри топика.
Партиции распределены между брокерами — кластер Kafka делает это автоматически при создании топика.
Consumer group
Консьюмер группа – это набор консьюмеров, объединенных одним ID, где вся группа слушает один топик и только один консьюмер вычитывает одно сообщение.
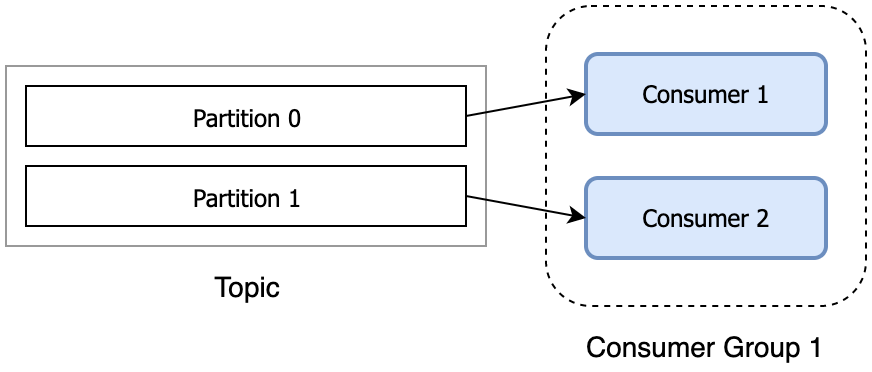
Если окажется, что нужно поставить третьего консьюмера, то надо ставить и третью партицию.
Или же, если нужно потреблять ивент другим consumer, то нужно создать отдельную consumer group.
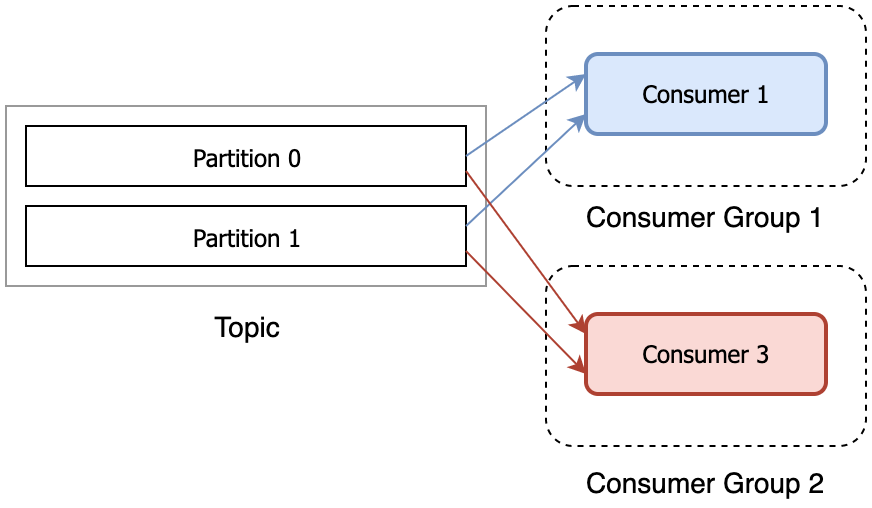
Reference: What is a consumer group in Kafka? - Coding Harbour
Conditioning stages
Репликация
Каждая партиция в Kafka имеет одну основную реплику, которая называется лидером. Именно лидер гарантирует упорядоченность сообщений в партиции и контролирует запись данных.
Каждая партиция также имеет дополнительные реплики, которые называются фолловерами. Реплики являются копиями данных из лидера. Они хранят данные в синхронизированном состоянии с лидером. Если лидер становится недоступным, одна из реплик может быстро перейти в роль лидера.
Лидер регулярно отправляет данные фолловерам, чтобы они могли обновлять свои копии данных и оставаться в синхронизированном состоянии.
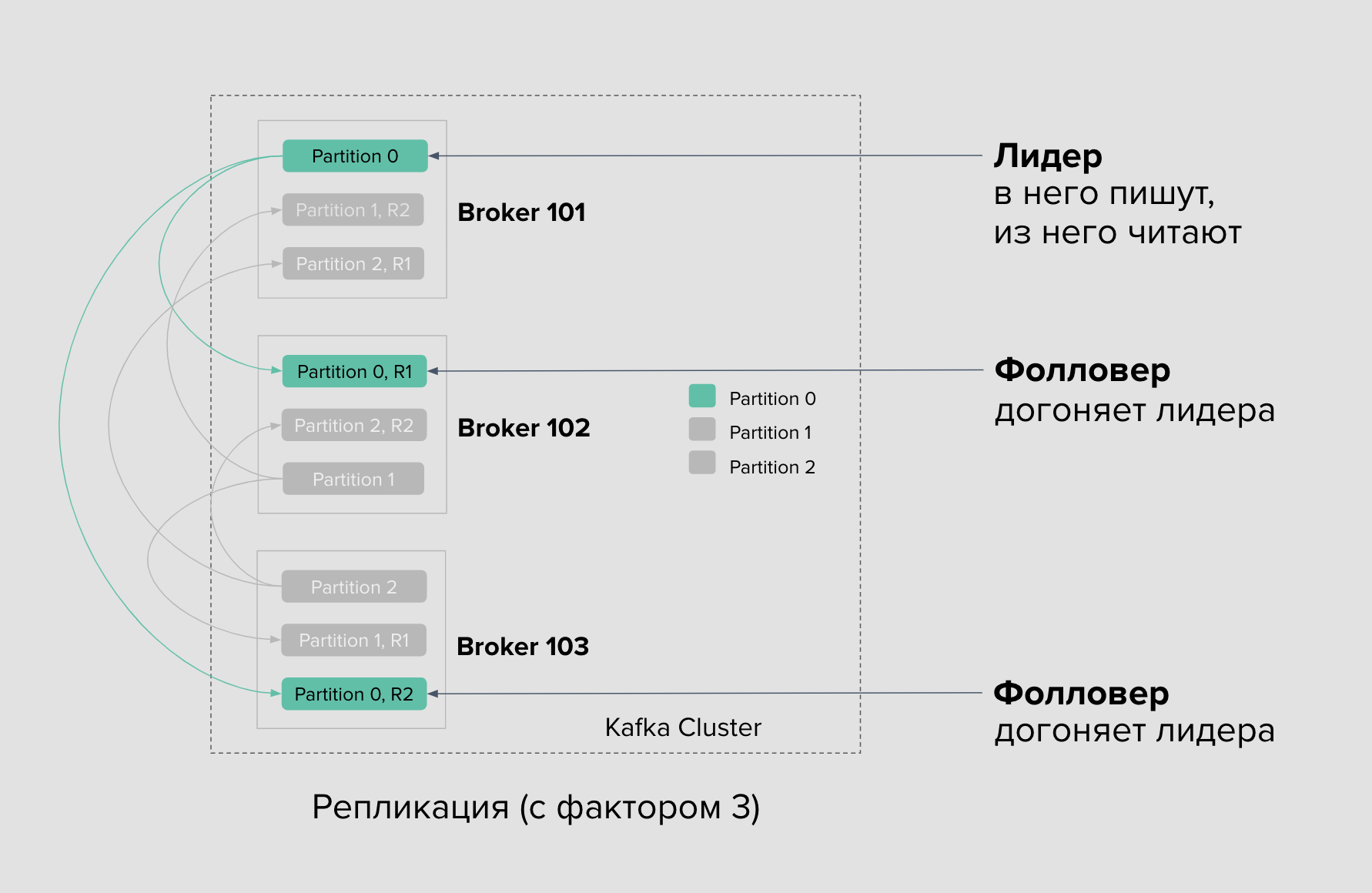 Клиенты, отправляющие запросы на запись данных, обращаются к лидеру. Лидер сохраняет упорядоченность и записывает данные, а затем реплицирует их на фолловеры.
Клиенты, отправляющие запросы на запись данных, обращаются к лидеру. Лидер сохраняет упорядоченность и записывает данные, а затем реплицирует их на фолловеры.
Фактор репликации отвечает за количество реплик.
Балансировка и партицирование

Если фактор = 3, то будет 3 партиции на 3 брокерах, но партиции будут в разных ролях. Где-то в роли лидеров, а где-то фолловеров.
Программа-продюсер может указать ключ у сообщения и сама определяет номер партиции, например, разделяя вычисленный хеш на число партиций. Так она сохраняет сообщения одного идентификатора в одну и ту же партицию. Эта распространённая стратегия партицирования позволяет добиться строгой очерёдности событий при чтении за счёт сохранения сообщений в одну партицию, а не в разные.
Если программа-продюсер не указывает ключ, то стратегия партицирования по умолчанию называется round-robin — сообщения будут попадать в партиции по очереди. Эта стратегия хорошо работает в ряде бизнес-сценариев, где важна не очерёдность событий, а равномерное распределение сообщений между партициями.
Также существуют List-based partitioning, Composite partitioning, Range-based partitioning и другие алгоритмы, каждый из которых подходит для своих задач. Вся логика реализации партицирования данных реализуется на стороне продюсера.
Дизайн продьюсера
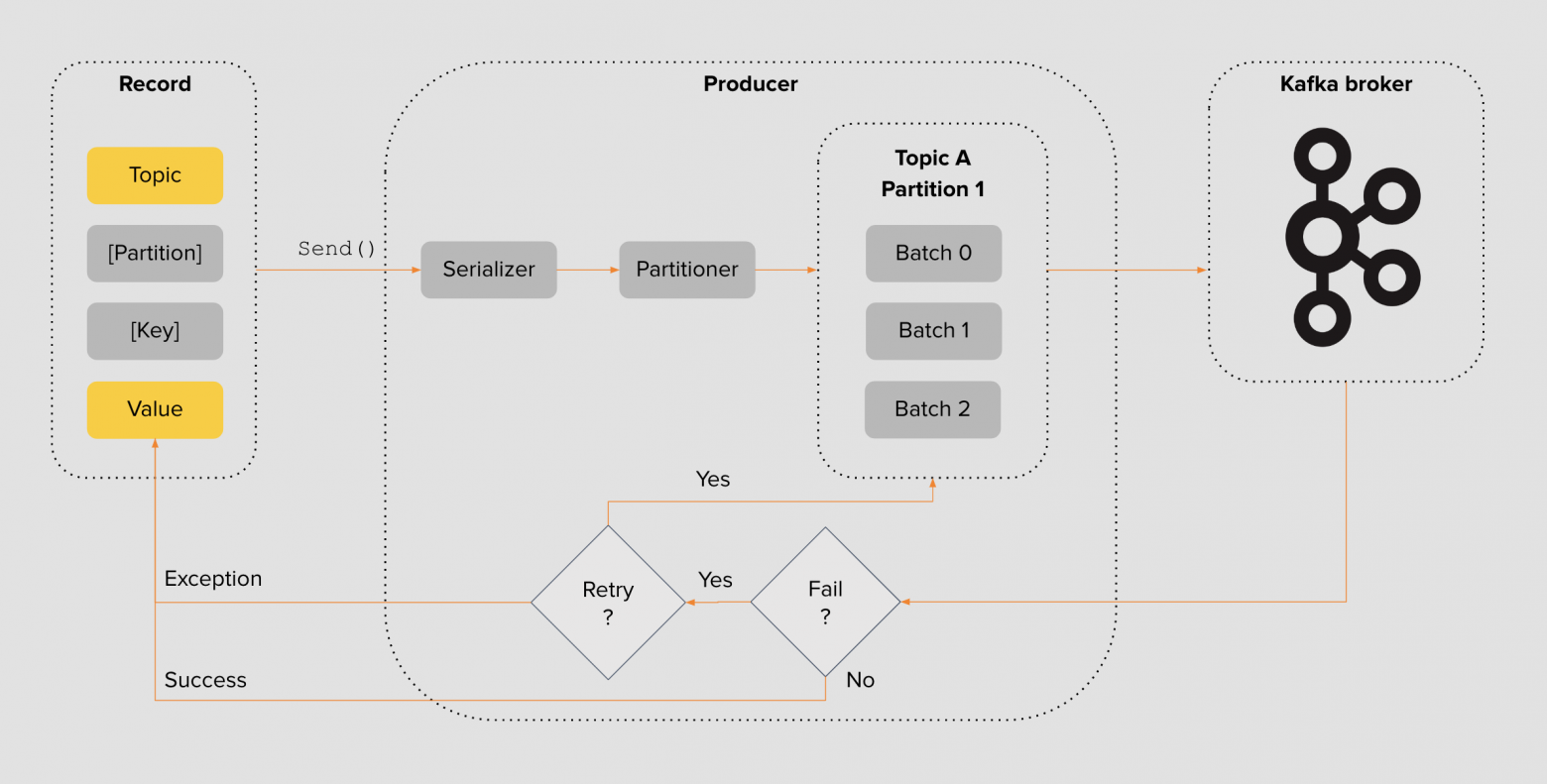
Payload упаковывается в структуру с указанием топика, партиции и ключа партицирования → сериализуется в подходящий формат — JSON / Protobuf → сообщению назначается партиция → группируется в пачки выбранных размеров и пересылается брокеру Kafka для сохранения.
Гарантии доставки
Со стороны продюсера разработчик определяет надёжность доставки сообщения до Kafka с помощью параметра acks. Указывая 0 или none, продюсер будет отправлять сообщения в Kafka, не дожидаясь никаких подтверждений записи на диск со стороны брокера.
Это самая слабая гарантия. В случае выхода брокера из строя или сетевых проблем, вы так и не узнаете, попало сообщение в лог или просто потерялось.
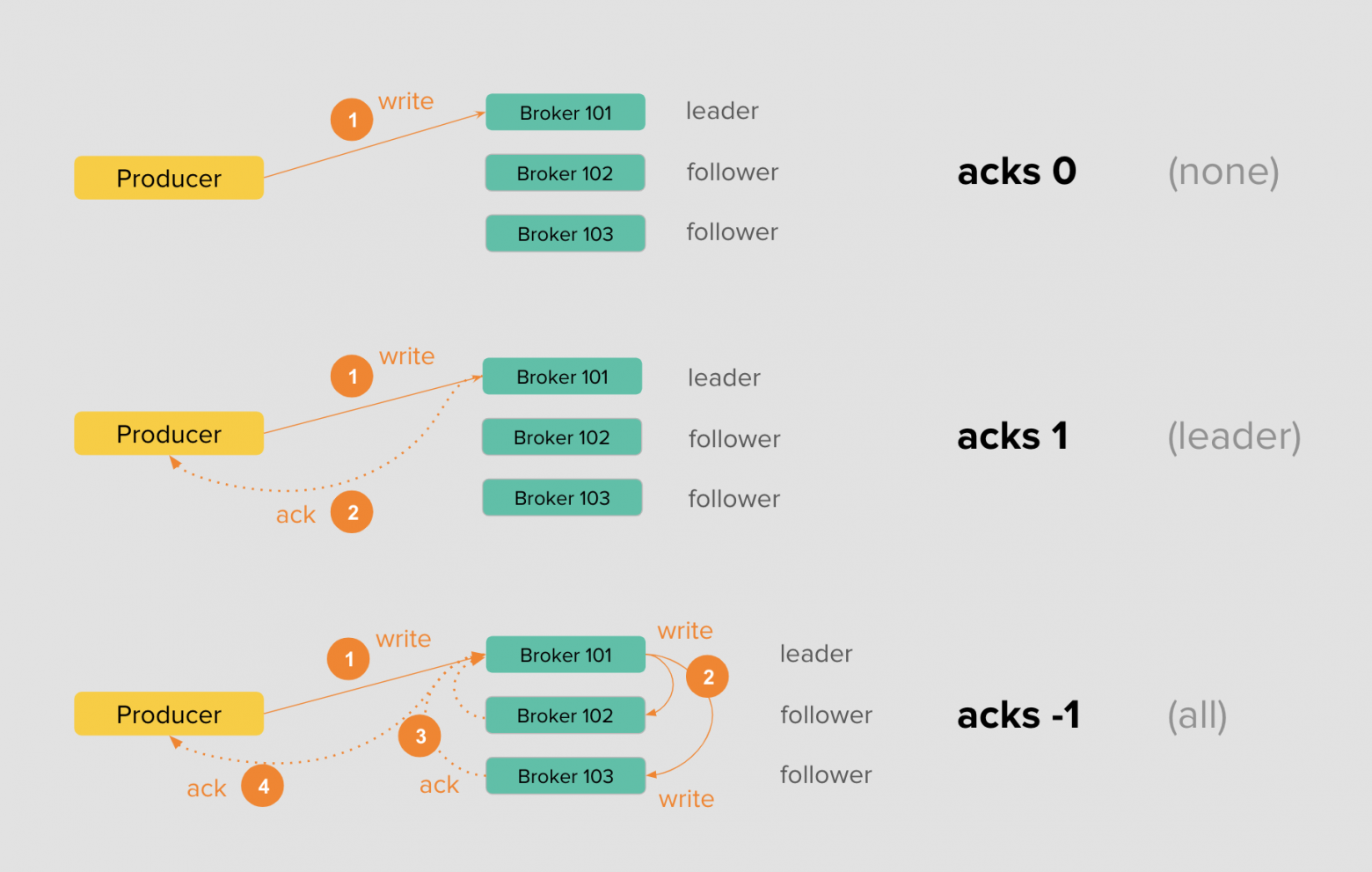
Указывая настройку в 1 или leader, продюсер при записи будет дожидаться ответа от брокера с лидерской партицией — значит, сообщение сохранено на диск одного брокера. В этом случае вы получаете гарантию, что сообщение было получено по крайней мере один раз, но это всё ещё не страхует вас от проблем в самом кластере.
Представьте, что в момент подтверждения брокер с лидерской партиции выходит из строя, а фолловеры не успели отреплицировать с него данные. В таком случае вы теряете сообщение и снова не узнаёте об этом. Такие ситуации случаются редко, но они возможны.
Наконец, устанавливая acks в -1 или all, вы просите брокера с лидерской партицией отправить вам подтверждение только тогда, когда запись попадёт на локальный диск брокера и в реплики-фолловеры. Число этих реплик устанавливает настройка min.insync.replicas.
Частая ошибка при конфигурировании топика — выбор min.insync.replicas по числу реплик. При таком сценарии в случае выхода из строя брокера и потери одной реплики продюсер больше не сможет записывать сообщение в кластер, поскольку не дождётся подтверждения. Лучше предусмотрительно устанавливать min.insync.replicas на единицу меньше числа реплик.
Очевидно, что третья схема достаточно надёжна, но она требует больше накладных расходов: мало того, чтобы нужно сохранить на диск, так ещё и дождаться, пока фолловеры отреплицируют сообщения и сохранят их к себе на диск в лог.
Преимущества Kafka
Горизонтальное масштабирование
Множество объединенных серверов гарантируют высокую доступность данных — выход из строя одного из узлов не нарушает целостность. Кластер состоит из обычных машин, а не суперкомпьютеров, их можно менять и дополнять. Система автоматически перебалансируется.
Чтобы события не потерялись, существуют механизмы репликации. Данные записываются на несколько машин, если что-то случается с сервером, он переключается на резервный. Кластер в режиме реального времени определяет, где находятся данные, и продолжает их использовать.
Принцип first in — first out
Принцип FIFO действует на консьюмеров. Чтение происходит в том же порядке, в котором пришла информация.
Вопросы на интервью
Можно ли вычитывать сообщения разными консьюмерами из одной партиции?
Обычно рекомендуется иметь не более одного консьюмера из одной и той же группы консьюмеров, читающего из одной партиции. Это обеспечивает упорядоченное чтение в рамках партиции.
Технически возможно иметь несколько консьюмеров из разных групп консьюмеров, читающих из одной и той же партиции. Однако это может привести к дублированию сообщений для разных групп консьюмеров.
Что если отправитель и получатель пишут много сообщений, попали в одну партицию?
Отправить их в отдельную партицию
Можно ли потерять сообщение, когда его отправили в очередь?
Ресурсы
RabbitMQ
- producers
- exchanges (how messages are routed—provide a great deal of flexibility)
- queues
- consumers
A producer pushes messages to an exchange, which then routes messages to queues (or other exchanges). A consumer then continues to read messages from the queue, often up to a predetermined limit of messages.
Producers add data to the tail of the queue; consumers receive data from the head of the queue. The queues are “first in, first out” with RabbitMQ: the first message in the queue is consumed first.
Преимущества RabbitMQ
RabbitMQ vs Kafka
Сценарии использования
- Kafka подходит для сценариев, где данные передаются между компонентами в виде непрерывных потоков событий, а также для аналитики в реальном времени (больше похожа на шину, чем на очередь).
- RabbitMQ хорошо подходит для сценариев, где необходимо гарантировать доставку сообщений в определенном порядке и обеспечить независимость компонентов друг от друга.
Сохранение сообщений
- Kafka сохраняет сообщения на определенное время (или скорее на любое время в объеме, на который хватит размера хранилища). Это позволяет обрабатывать и анализировать данные в любой момент времени, даже после их передачи.
- RabbitMQ хранит сообщения в очередях до тех пор, пока получатель их не обработает и подтвердит. После сообщение удаляется.
Порядок сообщений
- Kafka: не гарантирует
- RabbitMQ: гарантирует
Модели доставки
- Kafka добавляет сообщение в журнал, и консьюмер сам забирает информацию из топика
- RabbitMQ самостоятельно отправляет сообщения получателям — помещает событие в очередь и отслеживает его статус.
Гарантии доставки в Kafka vs RabbitMQ
Гарантии доставки в RabbitMQ
- надежностью сообщений — они не пропадут, пока хранятся на RabbitMQ;
- уведомлениями о сообщениях — RabbitMQ обменивается сигналами с отправителями и получателями.
Гарантии доставки в Kafka
- долговечность сообщений — сообщения, сохранённые в сегменте, не теряются;
- уведомлениями о сообщениях — обмен сигналами между Kafka (и, возможно, хранилищем Apache Zookeeper) с одной стороны и источником/получателем — с другой.
References:
- Apache Kafka и RabbitMQ: семантика и гарантия доставки сообщений
- RabbitMQ против Kafka: два разных подхода к обмену сообщениями
- Kafka VS RabbitMQ
Паттерны для брокеров
Request-Reply (Запрос-Ответ)
- Описание: Этот паттерн представляет собой двухстороннюю коммуникацию, где один компонент (запрашивающий) отправляет запрос, а другой (отвечающий) получает запрос и отправляет ответ обратно.
- Применение: Широко используется в синхронных операциях, где требуется немедленный ответ, например, в веб-сервисах или при удаленном вызове процедур (RPC).
- Технология: HTTP/HTTPS, gRPC, Apache Thrift
Publish-Subscribe (Публикация-Подписка)
- Описание: В этом паттерне издатель (publisher) отправляет сообщения без указания конкретного получателя, а подписчики (subscribers) получают сообщения на основе своих подписок.
- Применение: Используется для рассылки уведомлений, широковещательной коммуникации и в сценариях, где одно сообщение должно быть доставлено многим получателям.
- Технология: Apache Kafka, RabbitMQ, MQTT
Synchronous (Синхронный)
- Описание: Синхронная передача данных требует, чтобы отправитель ожидал ответа после отправки каждого сообщения.
- Применение: Подходит для сценариев, где важна тесная связь между отправкой запроса и получением ответа, например, в запросах к базе данных или при обработке транзакций.
- Технология: Традиционные веб-сервисы, SQL базы данных
Asynchronous (Асинхронный)
- Описание: В асинхронном обмене сообщениями отправитель не ожидает немедленного ответа и может продолжать свою работу независимо от того, обработано ли сообщение получателем.
- Применение: Асинхронные паттерны идеально подходят для фоновой обработки, длительных задач, обмена сообщениями в системах с высокой пропускной способностью и низкой задержкой.
- Технология: AMQP, Amazon SQS, Node.js
Competing Consumers (Соревнующиеся Потребители)
- Описание: В этом паттерне несколько потребителей (consumers) прослушивают одну и ту же очередь сообщений, и когда сообщение поступает, один из потребителей выбирается для его обработки.
- Применение: Эффективен для масштабирования обработки сообщений, распределяя нагрузку между несколькими экземплярами потребителей.
- Технология: RabbitMQ, Apache Kafka
Work Queues (Очереди Работы)
- Описание: Распределение задач между несколькими рабочими процессами, где каждая задача обрабатывается один раз одним рабочим процессом.
- Применение: Подходит для распределённой обработки задач, когда задачи могут быть независимо выполнены различными рабочими процессами.
- Технология: Celery (с использованием RabbitMQ или Redis)
Message Routing (Маршрутизация Сообщений)
- Описание: Определение правил или критериев для маршрутизации сообщений по различным путям или в разные очереди.
- Применение: Используется для управления потоком данных в системе, например, для фильтрации, агрегации или преобразования сообщений.
- Технология: Apache Camel, Mule ESB
Scatter-Gather (Разброс-Сбор)
- Описание: Отправка запроса нескольким получателям и последующий сбор и агрегация ответов.
- Применение: Подходит для ситуаций, когда необходимо выполнить параллельные запросы и собрать результаты, например, для агрегации данных из нескольких источников.
- Технология: Apache Kafka, Apache Spark
Fan-out/Fan-in (Разветвление/Схождение)
- Описание: Распространение сообщения на несколько получателей (fan-out) и последующее схождение результатов обработки (fan-in).
- Применение: Эффективен для параллельной обработки и последующей агрегации результатов.
- Технология: AWS Lambda, Google Cloud Functions
Cloud design patterns - Azure Architecture Center | Microsoft Learn